Guide to Computer Vision for Non-ML Experts


Machine learning can be daunting. After all, ML requires vast amounts of highly specialized skills and knowledge.
However, bringing ML to your company no longer requires hiring a team with PhDs in machine learning. The democratization of machine learning means that everyone from large enterprises to hobbyists can build ML solutions with nothing more than a good data set.
For example, developers and product teams simply need to understand their use case, data, and how they’ll integrate ML outputs into their product. Once they know this, they can evaluate the growing marketplace of “AI-as-a-service” solutions to find one that best supports their needs.
Computer vision — one field of machine learning — is accessible to any business with a relevant problem to solve. But the overly complex nature of most computer vision products, their docs, and resources hold many companies back from implementing it in their businesses. We want to change that.
Our goal with this guide is to help you understand what you actually need to know about computer vision, so you can evaluate the available CV SaaS solutions and choose the one that’s best for your use case.
Table of Contents
- Table of Contents
- What is computer vision?
- Computer vision terminology to know
- Computer vision examples — real life use cases
- Image classification: Online retailers sort products by type
- Object detection: Home gardening system detects plants in distress
- Optical character recognition (OCR): Media publications digitize historical print media
- Facial recognition: Border security at airports
- Scene reconstruction: Magic Eraser in Google Photos
- Image super-resolution: Medical imaging
- Computer vision hurdles (real and imaginary)
- A look at the computer vision APIs market
- Considerations when bringing CV to your business
- Nyckel: A computer vision API for non-ML experts
What is computer vision?
Computer vision (CV) is a field of machine learning where the goal is to have computers see and understand pictures, videos, and other digital imagery, much like a human would. While it sounds like a trivial task to those of us with two eyes and a brain, training a computer to identify objects, and understand all the context from visual data is a highly complex undertaking.
The discipline is valuable when there is a benefit to automating the visual processing that is normally done by humans. For example, spotting obstructions in the road for autonomous vehicles, detecting defects on a product before it ships to customers, reading a CT scan to spot medical anomalies with better accuracy than a human, or tallying headcount at a sporting event. Plus, computer vision isn’t just constrained to image data — it also works for other data formats, like audio and time series signals, that can be converted to visuals.
How computer vision works
The goal of computer vision techniques, like other fields in machine learning, is to identify patterns in data. ML experts do this by training complex models, usually deep neural network models, on vast amounts of visual data, with the computer eventually (hopefully) learning to distinguish differences between images.
Common computer vision techniques (or “function types”) include image classification, object detection, object tracking, pose estimation, and more — each with its own set of model architectures and models. For example, in image classification, Convolutional Neural Networks (CNNs) and Vision Transformers (ViT) are two popular model architectures, and ResNet and CLIP are examples of models of each type. Some of these models are publicly available, while companies privately own others. But for each, researchers developed the models intending to achieve a more exact or human-like result.
Thanks to the rapid progression of deep learning techniques used behind the scenes in computer vision, the discipline has emerged from labs and universities to mainstream applications over the past 10-15 years.
The importance of high quality data in computer vision
Well-annotated data is the foundation of training a good computer vision model for your use case. Here are four foundational principles to understand and adopt when it comes to your ML data:
- The data that you use to train your model should be “real-world” data from your system — not data that you deem similar.
- It’s critical to keep a human in the loop to catch and correct mistakes made by the model. You can identify model mistakes by having a human review a subset of the model’s outputs and then having that reviewer retrain the model with correctly annotated data.
- Human annotators make mistakes too, so it’s important to have a process in place to catch these incorrect annotations. You can uncover annotation mistakes with a data engine and then retrain the model with updated annotations.
- Your data can shift over time for various reasons, including shifts in consumer behavior or attitudes or broader socioeconomic trends. In these cases, your model’s predictions will become less accurate because the data that you used to train your model no longer aligns with your input data. It’s critical to keep an eye on this and retrain your model as necessary.

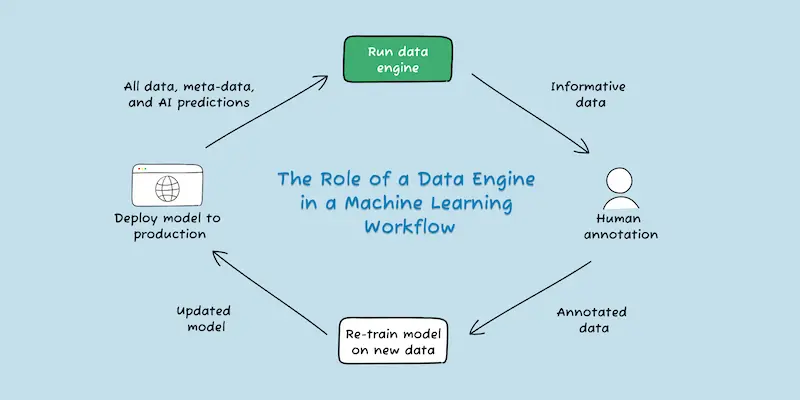
For the reasons above, iterating on your training data with the goal of fixing mistakes and continuously improving your model is the highest value activity you can do to build a strong computer vision system. Andrew Ng, a globally recognized leader in AI, calls the process of “systematically engineering the data needed to build a successful AI system,” data-centric AI. Data-centric AI is best done with a data engine that works in concert with your CV model. A data engine is your process of finding new, informative data that pinpoints where your model is making bad decisions. Identifying these problem cases allows you to retrain your model to be more accurate.
Computer vision terminology to know
As you think about how to use computer vision for your use case, you’ll likely come across various words to describe the different types of computer vision. Our Glossary of Computer Vision Function Types is a solid reference to keep on hand as you make sense of the many applications of computer vision.
In the glossary, we define some of the most common types of computer vision, including:
- Image classification: Used to categorize images using predefined labels. Image classification examples range from identifying AI-generated images to locating littered roads in a city.
- Image tagging: Used to label an image with multiple tags. Image tagging is another term used to describe multi-label classification, a type of image classification that allows you to tag an image with more than one label.
- Object detection: Used to identify the presence and location of certain objects in an image. (By the way, you don’t always need to use bounding boxes for object detection.)
- Semantic segmentation: Breaks down the pixels of an image to determine what each pixel is. Then, it labels each instance of the same object with the same label. (E.g.,river, forest, farmland in aerial imagery)
- Instance segmentation: Similar to semantic segmentation, instance segmentation breaks down the pixels of an image to determine what each pixel is. Then, it identifies and labels each instance of objects with a different label. (E.g., cat 1, cat 2, dog 1)
- Semantic image search: Text-based or image-based search of an image database to find matching images. (Check out our guide to semantic image search.)
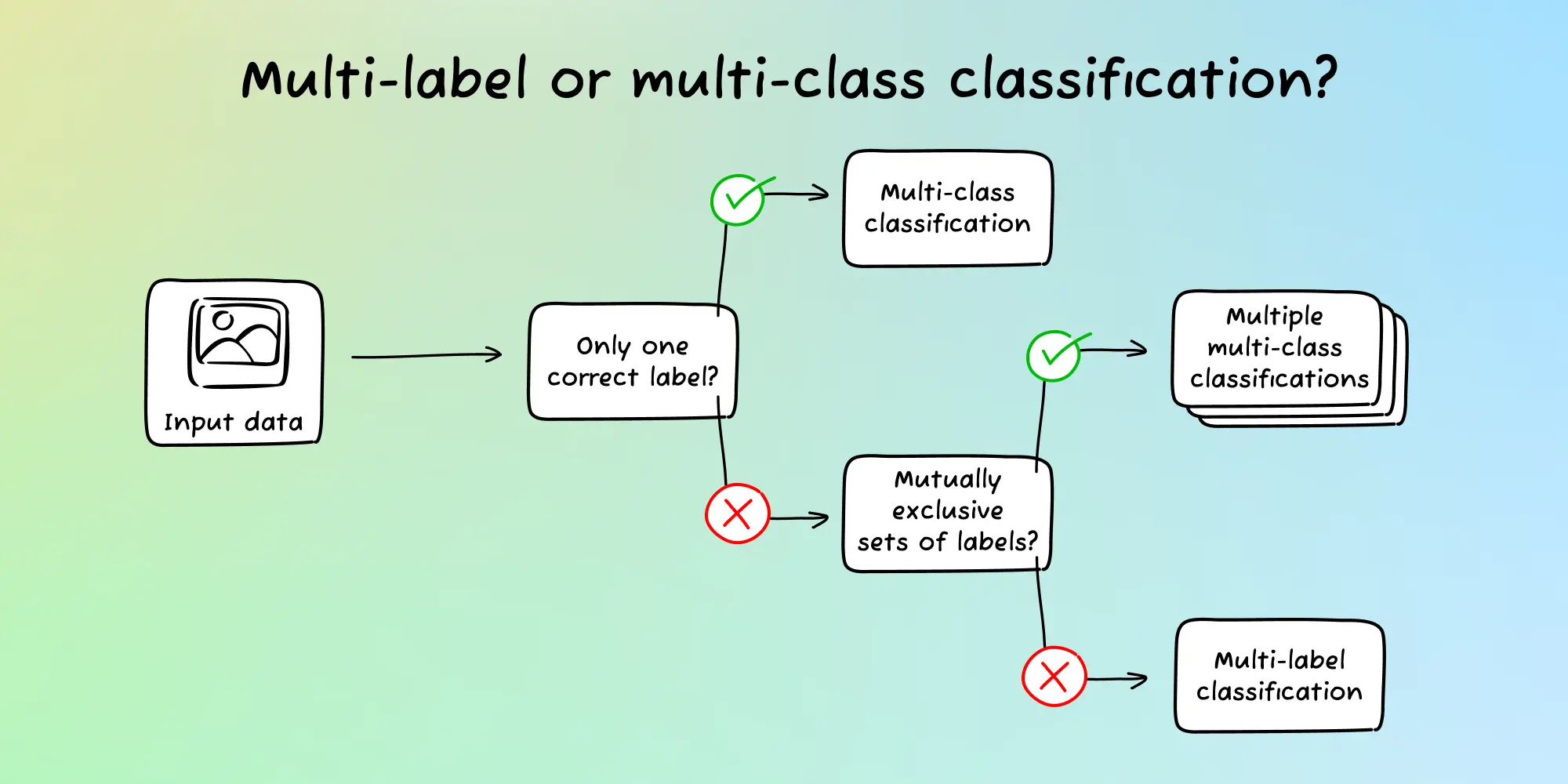
Image classification is one of the most fundamental tasks in computer vision. Terms that have particular relevance here are multi-class classification and multi-label classification. Our multi-class vs. multi-label classification article breaks down the differences between the two and when to choose each, but here are some quick definitions:
- Multi-class classification: Each image that you are classifying can only be assigned to one correct label. For example, a picture of an animal is either a cat, dog, bird, or snake.
- Multi-label classification: Each image that you are classifying can belong to multiple labels. For example, an item of clothing can have the colors red, blue, green, yellow, or purple.
Now that we have this computer vision terminology straight, let’s explore some computer vision examples.
Computer vision examples — real life use cases
Computer vision techniques are applicable to most industries and have what can feel like infinite use cases. Using computer vision effectively is a matter of imagining where these technologies will make a real difference. The following computer vision examples are just a few of the many that have already been tried in real life.
Image classification: Online retailers sort products by type
Online retailers use image classification for their product catalogs to help categorize and tag products based on their attributes. For example, a shoe could be tagged by its type (sandals, slippers, sneakers, boots) which can then be used for custom sorting by the customer as well as analytics for the business.
Object detection: Home gardening system detects plants in distress
While everyone can grow plants in their home, not everyone knows how to keep them the most healthy. Instead of consulting the web every time a plant is in distress or not growing as it should, computer vision can be used to inform growers what to do next. Gardyn has outfitted its smart, indoor vertical hydroponic systems with cameras that capture pictures of its customers’ plants. Using object detection, Gardyn now detects when a customers’ plant is in distress and notifies them via their app.
Optical character recognition (OCR): Media publications digitize historical print media
The process of turning paper-based print media into searchable, digital print media might seem like a fairly trivial task now, but it wasn’t always this way. Thanks to OCR research over the past few decades, we are now able to digitally search newspapers (like editions of The Times from the 1700s) for keywords, when previously it was necessary to trawl through microfiche archives. This brings to life historical works, making them indexable and searchable for new generations.
Facial recognition: Border security at airports
Given how seriously many countries take border control, it may not come as much of a surprise to learn that many international travelers are now being processed in airports by facial recognition technologies. Now, rather than a physical agent checking a passport against your own appearance, technology such as the US’s Simplified Arrival can assess whether a passenger’s details on file match their own face through feature extraction.
Scene reconstruction: Magic Eraser in Google Photos
Google Photos now has the ability to “remove photobombers with Magic Eraser.” Thanks to scene reconstruction technology, it is possible to remove people, trash, or other unwanted objects from your photos like they never existed, without having to edit the image manually. A task that used to take professionals hours in Photoshop is now available instantly at everyone’s fingertips.
Image super-resolution: Medical imaging
Visualizing what’s happening inside of our bodies is critical for many health applications, yet camera work is often very invasive, and often not possible at all. Instead, the practice of combining MRI results with image super-resolution, a type of computer vision, shows promise for enhanced imagery. In a recently published study, utilizing particular super-resolution techniques in combination with non-invasive MRI showed promise in practices where catheter insertion may not be an option.
Have an idea for a computer vision use case? Sign up for Nyckel to build a function for free. Reach out to us any time for help brainstorming the best way to solve your problem.
Computer vision hurdles (real and imaginary)
The underworkings of computer vision are a complicated science, which holds many people back from getting started on their CV project. But are the hurdles getting in your way real? Or are they imaginary or a result of a misconception? Here are a few of imaginary hurdles we see a lot of businesses running into, plus a few real ones you will likely need to overcome.

Imaginary hurdles in computer vision
1. You need a mountain of data
It’s true that training a machine learning model from scratch can require a large amount of data, depending on the complexity of your task. However, these days, you’re able to leverage pre-trained models to significantly cut down the amount of data you need to develop a novel solution by using transfer learning. For example, we were able to build an image classification model that predicted with 87% accuracy whether a chest X-ray depicted pneumonia or not using only 10 pieces of data (5 images per class).
2. It will take a long time to implement
Historically, computer vision has taken a long time to implement for a few key reasons. First, training and deploying a computer vision model required you to have specialized (i.e., expensive) resources on staff. Even companies with machine learning teams on staff had to compete for the limited availability of these resources, making ML projects slow at best. Second, computer vision takes a lot of data processing power, so just training your model used to take days. And third, it’s time consuming and difficult to build a data pipeline to train and continuously improve the model with new data.
Fortunately, these hurdles have been mostly overcome thanks to computer vision platforms that 1) no longer require ML expertise to use and deploy models, 2) use transfer learning from pre-trained models to make training faster, and 3) make it easy to add informative data back into the training set to automatically retrain the model.
3. You need experts on the team
We mentioned this above, but let’s dive deeper into the inaccurate assumption that you need ML experts on staff to train and deploy ML models. While traditionally, computer vision tasks required specialized machine learning professionals to train, deploy, and monitor models, this is no longer true in many cases. The barrier to entry for some machine learning tasks is not the difficult, complex, and expensive process it once was. Instead, we now have access to AutoML products that remove the complexity of machine learning so that developers and product owners within a business can create and deploy ML solutions themselves.
Real hurdles in computer vision
1. Real-world, annotated data is required
To train models correctly, you will need to annotate a real dataset. Each image or video that you use to train your model will need to be labeled correctly, which is typically a task for humans. The more labeled images you have, the better your results will be. This can be a tedious process, but it can be accelerated by using an ML SaaS platform that makes annotation easy and only needs a small dataset to perform accurately. Plus, getting started with small amounts of data, collecting more of the important data on the deployed model, and annotating more of this data over time can make this an iterative process that is less daunting than having to do everything up front.
2. Human review is required
Your computer vision model will not always recognize the data the way you want it to. As a result, you will always need a step of manual intervention in your otherwise automated process. For example, we recommend sending any ML decision below a certain confidence threshold to a human for review. This not only helps ensure your model’s accuracy, but you can feed these difficult cases back into the training data so your model can improve over time. We call the process of managing this informative data and improving your model a data engine.
3. Data drift might occur
You’ll also need to monitor your model for data drift, which is when the data on which you deploy your model becomes different from the training data. This requires you to annotate new data and retrain your model.
Developing custom computer vision solutions no longer has the barriers to entry that it once did, thanks to the availability of pre-trained models, transfer learning, and AutoML solutions. While it still requires a not insignificant amount of labeled, clean data, and humans to choose the right solutions and moderate results, the barriers to entry are much, much lower.
A look at the computer vision APIs market
Worldwide, the computer vision market is growing, valued at USD 14.10B in 2022 and expanding at a compound CAGR of 16.6%, according to Grand View Research. While much of this consists of hardware components, the software side has the highest growth rates. Only in more recent years have software solutions become available for markets beyond industrial and large enterprise applications.
The computer vision market is expanding, with a range of large, multi-purpose solutions, as well as boutique providers who fill niche business needs. For most businesses, the right-fit solution is one that is self-service, does not require machine learning skills, and is full stack, meaning the solution provides data annotation, AutoML (training), and deploy functionality in a no-code or low-code environment without any extra software.
What are the top computer vision SaaS tools?
While people may be familiar with the big three’s products, Google Vertex AI, Azure Custom Vision, and AWS Rekognition Custom, there are also independent providers that offer customized, end-to-end computer vision technology solutions. These include Nyckel, Ximilar, Roboflow, Hasty, Clarifai, and Levity.
Our qualitative analysis of these computer vision platforms compared their functionality, the amount of time it took to train a model using each, model performance, company positioning, and pricing. We found significant variations across products in terms of accuracy, user experience, and pricing structures. Here’s a quick summary of how each platform performed:
- Nyckel: Super quick and accurate with a breadth of ML services
- Vertex AI: Steep learning curve with solid accuracy and helpful user tutorials
- Azure Custom Vision: Getting started is an absolute headache, but the model performs accurately
- AWS Rekognition Custom Labels: Tedious set-up; deployment required coding, so we couldn’t test its performance
- Roboflow: Computer vision platform for enthusiasts who want to get into the details
- Ximilar: User-friendly and accurate with a narrow focus on computer vision
- Hasty: Low performance & usability — but may perform better with image classification (if the option exists)
- Levity: Easy-to-use with many no-code integrations, core ML performance lagging others
- Clarifai: The OG offers a comprehensive product suite in a somewhat confusing platform
Where does Nyckel fit into the computer vision market?
Nyckel offers the following computer vision APIs:
Other platforms that offer image regression, instance segmentation, or semantic segmentation may be a better fit if this is your use case (although we’re always expanding our functionality).
Curious how Nyckel’s image classification API performs against Google, AWS, and HuggingFace? Check out our image classification benchmark to see how we compared on performance, training time, latency, throughput, and developer experience.
Considerations when bringing CV to your business
So, you’ve decided that a computer vision function is going to be an asset to your business. How do you know what that should look like? Do you need to hire? Can you get away with an AutoML solution? And what sort of data is needed?
Do you need to hire an ML team?
For many problems and businesses, you do not need an ML team. Not only are machine learning experts expensive and difficult to hire, it is no longer necessary with the availability of low-code/no-code end-to-end AutoML solutions that are now available. Common computer vision tasks like classification, object detection, and segmentation are covered by many AutoML services. When your project requires computer vision tasks that fall outside of these well-trodden ones, you might have to hire experts in the field. Otherwise, hiring an ML team will likely negatively affect your organization’s agility.
How ML serves your users and is integrated into your product is your edge against competitors, not the fact that you built the model in-house. Building entire solutions in-house is expensive, time-consuming, and rarely provides differentiated value to your customers. Getting it right for things like retraining in the presence of new data is not trivial. Not only this, the state of the art in ML changes very quickly and new techniques will come along that outperform your hand-built model.
Instead, pick solutions that give flexibility with the complexity abstracted away, and only add team ML specialists when you’ve exhausted other options. Go with a service-oriented architecture for your ML function to reap the benefits.
AutoML for computer vision
AutoML is the preferred option for businesses looking to implement computer vision ML without needing expert assistance.
What is AutoML?
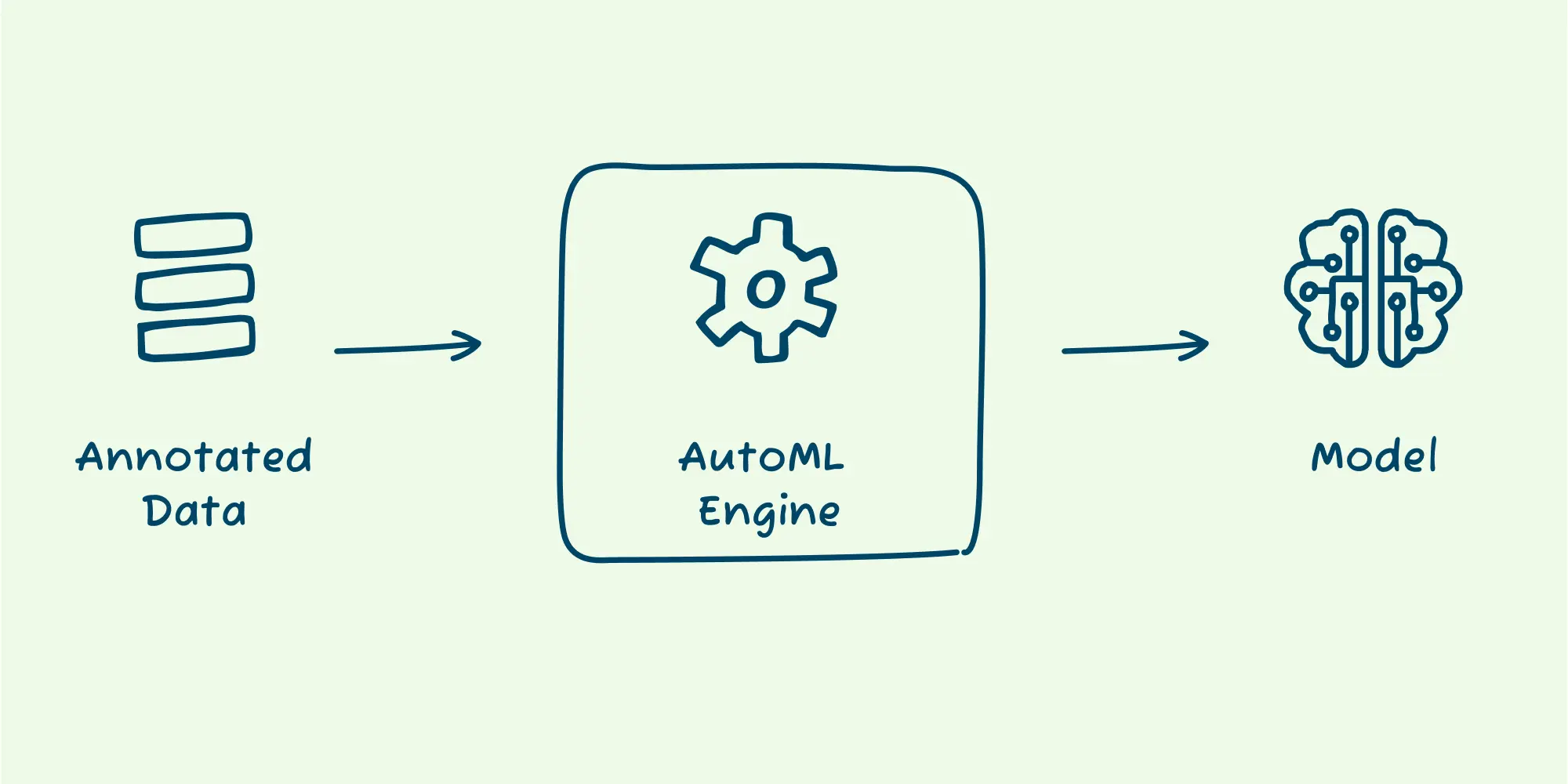
AutoML is just what you think it is - automated machine learning. These are tools that automate the training and optimizing of machine learning models. AutoML will often automate or assist with tasks like data preprocessing, feature engineering, and hyperparameter tuning.
AutoML solutions abstract away what an ML engineer would usually do to create a model: they try out different data augmentation, models, training techniques, and hyperparameters to find the one that maximizes the accuracy for your data. While this process requires expertise and is error-prone, it can be automated.
While AutoML is not as flexible or transparent as custom solutions built from scratch and may not fit highly specific use cases, the benefits for most users far outweigh the downsides.
A production-grade ML solution needs more than AutoML
While AutoML is a powerful way to automate many of the complexities of training an ML model, automated training is still only one component of the entire machine learning workflow. Production-grade machine learning SaaS solutions can and should expand beyond AutoML to incorporate other aspects of the ML process. We call solutions that span the entire ML development pipeline “end-to-end AutoML solutions.”These solutions include functionality that enables:
- Data labeling: Allows for the ability to annotate data effectively and efficiently.
- Model deployment: Includes deployment functionality that considers how to optimize cost, latency, throughput, scalability, and more, and allows you to easily redeploy retrained models.
- Model monitoring: Allows you to monitor the performance of your model by capturing important data from invokes, so you can spot problems like data drift and incorrect annotations.
- Model retraining: Makes it possible to retrain your model by adding newly annotated data to your model. (Many AutoML solutions train models as a one-time thing— making it impossible to retrain or improve the performance of that model.)
- Active learning and data capture: Enables you to capture important data points that are most likely to improve the model as the model is invoked (e.g., data from rare classes or data similar to where the model makes mistakes) and then allows you to annotate new data to retrain the model on that important data.
Having all of these components of the machine learning workflow in one place is what enables you to spot erroneous annotations and areas of data weakness — and then easily iterate on your data to improve your model. As we mentioned before, iterating on your data to improve your model is the highest value activity you can do to build a strong CV system. End-to-end AutoML solutions also increase speed and ease of your development workflow because you don’t have to switch between various platforms and paradigms to complete your ML development loops.
Piecemeal ML solutions
Instead of an end-to-end AutoML platform, you can use piecemeal solutions that perform one or a handful of the above tasks. For example, there’s Labelbox, which is scalable AI for annotation, Aquarium Learning for data management, AWS Sagemaker for training models, Weights and Biases for tracking training experiments, Valohai or Determined.ai for MLOps, and AWS or other clouds for deployment.
The issue with using piecemeal solutions is, of course, that you have to stitch together the pieces yourself and they don’t always fit perfectly. This adds friction to the whole process and forces you to care about things that are not core to the problem — things like training infrastructure, data pipelines, MLOps, model choice, deployment infrastructure, etc.
End-to-end AutoML solutions are often the best approach for most businesses looking to implement a computer vision system. Additionally, when training is quick, you don’t have to strive for perfection with your first model — mistakes and problem cases can be caught and solved easily later. This iterative approach is possible because (certain) end-to-end solutions allow you to annotate your data quickly, get started with just a few data points, capture important data that informs you about new data you need to annotate, and improve the model on the fly as you annotate more data to solve for these problem cases.
Nyckel: A computer vision API for non-ML experts
Nyckel is an easy to use, end-to-end AutoML solution. Our platform is designed to:
- Make the barriers to entry to machine learning as minimal as possible — you don’t need any ML or infrastructure expertise.
- Ensure best-in-breed performance without all the configuration of a piecemeal tool or complexities of an in-house solution.
- Be end-to-end by combining an annotation tool, data engine, fast training, instant deployment, and model monitoring.
- Get to production quickly (sometimes in as little as a day) by allowing you to start with minimal data and continuously improve as you go.
We believe integrating machine learning into your products doesn’t need to be as hard as many people make it seem. We designed Nyckel to be quick, accurate, and easy-to-use and provide a full-suite of computer vision ML capabilities for businesses that don’t have ML experts on staff.
Have a computer use case to tackle but aren’t sure what to do next? Here are a few options:
- Sign up for a free Nyckel account and start building your first function.
- Explore our quickstart guides.
- Discover how other customers use Nyckel for their computer vision needs, including Pet Media Group, Gardyn, and Spyscape.
- Reach out to us if you need help brainstorming the best way to approach your problem.
Our qualitative analysis of the top computer vision SaaS players compares platforms on functionality, the amount of time it takes to set up a model, performance, positioning, and pricing. See the complete analysis.