9 Ways to Use a Data Engine to Improve Your ML Model

Teams looking to increase the accuracy of their ML systems can do so in two ways: 1) Through better models (i.e., better model architecture/neural networks and/or training architecture), or 2) better data. Generally speaking, it is well-established that improving your data is the more effective of these routes.
After all, machine learning is fundamentally about compiling data into a model to build a function. How you annotate your model’s training data helps the model predict how you would classify new data. In other words, the training data you select and annotate determines what the model will output and ultimately shapes the model’s accuracy.
Given that your function’s accuracy depends on your data, it’s worth thinking carefully about the quality of your training data. However, when you deploy a new model, borderline cases will always cause problems; the model simply won’t always recognize the data the way you want.
These problems require manual intervention in your automatic classification process. You will need to manually annotate some problematic data — data that you choose precisely because it’s problematic. We like to call this “informative data.” Manually annotating these difficult cases will be the most effective way to update your model. It will also highlight aspects of your data pipeline that weren’t quite as robust as you initially assumed.
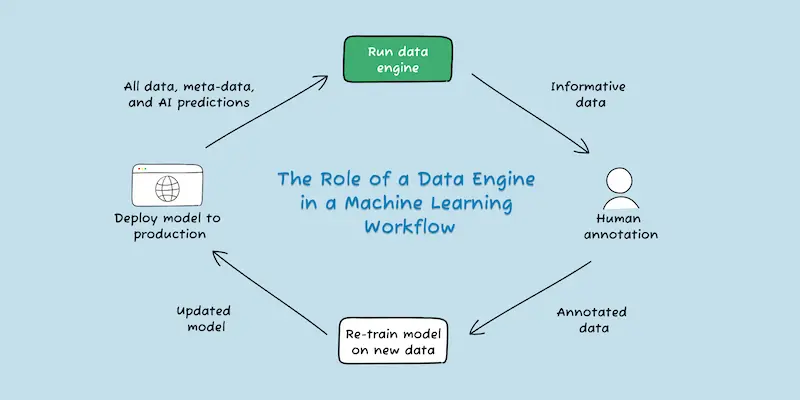
But what’s the best way to detect and manage problematic data (what we call informative data)? Let’s look at how you can improve your data workflow – what we refer to as a “data engine.”
What is a data engine, and how can you improve it?

A data engine is a process for finding new, informative data. This means leveraging your existing workflow to find problem cases that illuminate where your model is making bad decisions. Identifying these problem cases allows you to retrain your model to be more accurate.
If your model is having a hard time classifying certain data based on its past training, then giving the model more information about this problem data will improve its accuracy. In this article, we’ll review nine data engine methods to put into practice to find informative problem data.
1. Random sampling
Random sampling is likely already part of your regular quality control. You might be sampling as much as 1% of your data to manually check that your automated system is producing accurate classifications. Random sampling will eventually pick up all types of informative data, but the approach is, by definition, unsystematic. It doesn’t prioritize the most common types of problem cases, doesn’t ensure timely coverage of all types of problems, and important empirical facts about the quantity and quality of problem cases may remain siloed in the heads of human moderators.
In short, we can do better. However, random sampling is still an important part of the mix. If you didn’t use random sampling and instead focused exclusively on a targeted subset of problem data, it would skew your model’s training over time and, again, harm accuracy. So, keeping around 10–25% of your manual data review random is sensible. But what about the other 75-90%? The remaining eight methods in this article focus on “active” sampling methods that will help ensure you tackle problem cases efficiently.
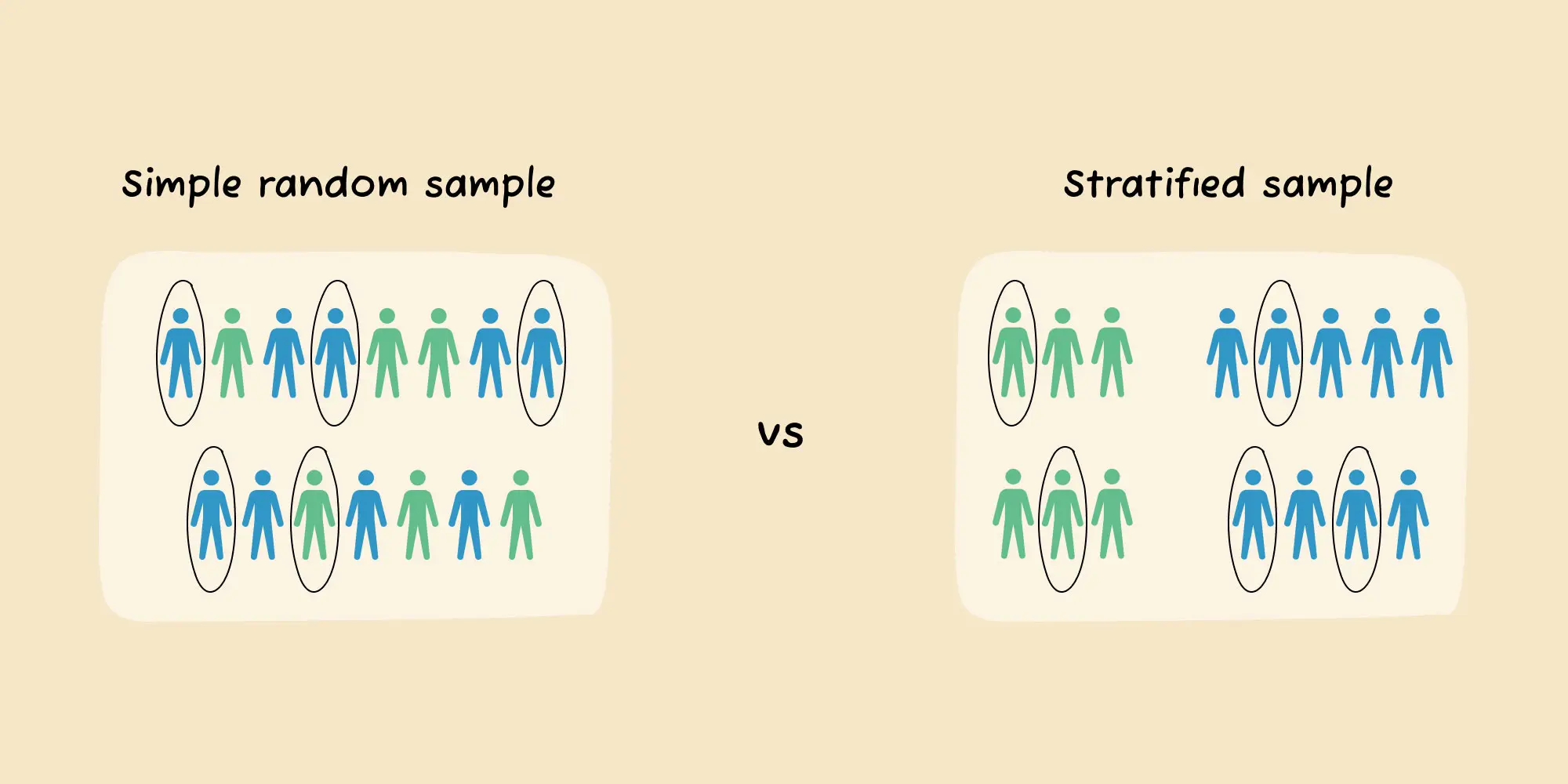
2. Stratified sampling based on metadata
You can use metadata – supplementary data that you normally collect alongside primary data (e.g., the time and location of data collection) – to ensure coverage of your full range of data collection situations. A sample that includes similar amounts of data across several relevant situation types is called a stratified random sample.
For example, in the case of a toll booth classifier that takes pictures of vehicles and classifies them to determine the appropriate toll for each driver to pay, a stratified random sample could include images taken in different weather conditions, at different times of day, and in different seasons. You can extract these situations using metadata (e.g., possibly by using timestamps together with a weather report). Purely random sampling, in contrast, would over-represent images captured during the day since there is more traffic, and therefore more pictures taken overall during the day. This would train the model to do well on the daytime images but not on ones captured at night.
3. AI confidence score
Perhaps the most obvious way to directly target problem data is to look at cases your AI classifies with low confidence scores. In a nutshell, simply send data where the model has low confidence for human review and annotation and then re-train the model. Focusing on data with low confidence scores provides more systematic coverage of borderline cases than would happen in a random sample.
Note, however, that in this method, you rely on the model to grade its own homework. You’re using the model’s confidence scores to measure its success. In other words, the same model you’re trying to improve is also producing the scores. It would be more reassuring to get a more objective, model-external metric of the model’s success. Let’s look at how to do that next.

4. Model ensemble agreement
Model ensemble agreement is the extent to which a group of models agrees on the same answer. The basic principle is to train multiple models on the same data and compare their classification decisions. If there’s a data point where the models don’t reach a clear consensus in their classifications, then that data point is probably informative for retraining your model.
A model ensemble could either comprise models of the same type/architecture or models with different architectures. Even models with the same architecture will predict slightly different results because the training process has random elements that will vary between the two models. Either way, you can use a model ensemble to pinpoint where answers vary.
5. Deploy-phase data augmentation
Another approach is to use a single model but feed it an augmented version of the same data multiple times. For image data, this could mean changing the hue, saturation, or applying light cropping. If it’s a good model, your augmented photos won’t fool it; the model will classify them the same as the original images. However, if it flips to different classifications for some images, then those data inputs are interesting cases to consider for manual review and model retraining.
No matter what kind of data you’re using, low confidence values or discrepancies between model ensembles or augmented data sets will always uncover your model’s weakest performance areas. But, in addition to these general methods, you may want to investigate domain-specific tactics.

6. Spatio-temporal consistency for robotics
Imagine you have an image classifier deployed on a robot. When your robot takes a picture, it typically also stores useful metadata, such as the robot’s position and some physical facts and data about the robotic system, such as its limits and tolerances. This metadata allows you to spot classification decisions that fail a spatio-temporal smell test.
For example, let’s say a model classifies an image as having a person in it. But in photos captured a few milliseconds before and after that image, there were no people in them. Since people can’t move very far in a few milliseconds, this suggests a bad decision by the classifier.
Similarly, if the robot is set up to recognize furniture from people, and it recognized a couch in the corner of the room this morning, we might expect the same classification decision this afternoon based on what we know about how furniture normally behaves. If the robot identifies a chair or empty space in the same location later in the day, something is likely wrong with the image classification model, and we have just discovered a set of informative samples to annotate and re-train on.
In both of these cases, we’re using our prior beliefs about the spatio-temporal consistency of the world (not the model) to spot potentially incorrect classification decisions. This approach is useful when we know a lot about the system capturing the image data, but not in cases where, for example, users are classifying images from diverse contexts.
Once you’ve identified some error cases, manually updated their annotations, and retrained the model, you want to see if the model is now classifying similar cases correctly. But how do you find similar error cases? Similarity embeddings!
7. Offline teacher models for IOT
Imagine you have an AR game requiring you to capture images via your phone for classification. Your phone’s limited memory and processing power means that you are limited to using a small AI model for this real-time decision-making. In such situations, one can use a teacher model to identify informative samples as follows:
In addition to the small AI model, which runs on your phone, you also train a much larger “teacher” model on the same data. This model would be too large to run on the edge device, but it can run offline in the cloud. However, because it is larger, it will likely be more accurate.
The idea is to use the smaller model to make real-time decisions for the application. Then, to send the image to the cloud for offline processing by the teacher model. Images where the two models disagree are worth sending for human labeling since the smaller model likely made a mistake.
Once you’ve identified some error cases, manually updated their annotations, and retrained the model, you want to see if the model is now classifying similar cases correctly. But how do you find similar error cases? Similarity embeddings!
8. Similarity embeddings
Similarity embeddings are vectors in high-dimensional space that a neural network uses to represent image data. These vector embeddings encode semantic information that a model abstracts from image data. So, when a model generates vector embeddings for unlabeled image data, it is effectively predicting the semantic content of the data. This is the basis of similarity search: if we have a piece of image data, we can use a model to search for similar images.
In the case of a data engine, we can use this method to identify informative data. Once you have identified data that the model struggles to identify correctly, you can use a similarity embedding to find more images that are similar to it. Then you can manually annotate these images and feed them back to the model.
However, even in the realm of a thousand dimensions, vector embeddings are still abstractions; the original picture would have had as many dimensions as pixels. To get a feel for why this level of abstraction is still useful, take a look at this two-dimensional representation of an image data set:

You can likely see similarities even in this very low-dimensional space. But the process of dimension reduction from image to model vector embeddings means that the semantic content of the embedding may fail to capture something salient to human eyes, or it may over-emphasize something trivial.
For example, say our toll booth computer vision system erroneously classified particular car models as buses. To improve the model, we want to find, annotate, and re-train on more examples of such car models. In this case we don’t want extraneous features of the original image, such as weather conditions, to be considered in a similarity search. We can fix this issue using search helper models.
9. Search helper models
A helper model tackles the genericity problem by being very specific in its own function. For example, if our toll booth system keeps incorrectly classifying Jeep Wranglers as buses, we want to find more images of Jeep Wranglers (in order to re-train and improve our main model). To do this we could train a helper model specialized in doing exactly that.
Thus, a side effect of trying to identify Jeep Wranglers is that we produce a model that is excellent at classifying Jeeps, which is not what we initially built the computer vision system for. However, we can use the classification decisions of this helper model to find informative data, which we then train on to improve the main model.
Start detecting and managing informative ML data
There are many ways to discover informative data to improve your model’s performance. The model’s own confidence scores are a natural starting point because it uses data you already have once your model is up and running. Comparing classification decisions among ensembles of similar or architecturally different models is a more objective investigation that requires additional building time. Another approach is to augment your deployment data stream to see whether your model is robust enough to classify it in the same way.
Your image meta-data is also a rich source of information that can explain bad decisions by your model. Considering the spatio-temporal context of your image capture system may help here, or you may need to generate a stratified sample that covers a variety of situations in a balanced way.
Considering which part of your data engine to build first? Your ML program, specific use cases, and business model can help you prioritize which method to focus on first. Reach out at any time if you’d like to brainstorm how to detect and manage informative ML data.