What is class-balance drift, and why does it matter for content moderation?

Class-balance drift is a common type of data drift that can cause your content moderation system to become less accurate over time. In this article, we look in detail at what class-balance drift means and what to do about it. But first, let’s refresh our memory about data drift in general.
What is data drift?
Data drift comes in various shapes. In the context of statistical modeling and machine learning, data drift means that the data on which you deploy the model has become different from the training data. For example, your user generated content (UGC) might change in character over time, or you might deploy an existing model in a new context. When data drift happens, it is difficult to predict how your model will behave.
Why is that? From a machine learning theory perspective, all common learning methods (including stochastic gradient descent, which is used to train deep neural networks) make the so-called IID assumption: that the data is independent and identically distributed.
The IID assumption requires that the samples (both the train and test sets) are drawn from the same distribution, and that the distribution is static, meaning that it does not change over time. If this assumption holds, then the theory can closely predict the number of errors the model will make. If this assumption is violated, however, as it often is in practice, you can’t confidently say whether the model is accurate until the model is in production and you notice that your auto-moderation performance is dropping.
Let’s look at some ways in which data drift can occur.
- Temporal changes. The time of day, day of the week, and certainly the time of year affect data distributions. For example, the changing colors and appearance of nature with the seasons will be relevant if your model consumes imagery.
- Major events. Major sporting events or technology breakthroughs cause a surge of activity across forums. So do tragedies such as terrorist events and school shootings.
- Cultural acceptability drift. As culture changes, what is considered acceptable also changes. Some words that were in common use just a few years ago are today regarded as unacceptable. For example, standard language increasingly uses gender-neutral pronouns by default.
- Game-theoretic aspects. Malicious users may adjust to your current moderation enforcement in an effort to circumvent the defenses. For example, a spammer may try to circumvent a spam filter by tweaking the content.
- Train-deploy mismatch. If your AI is trained on canned data (e.g. from Kaggle) that is different in character from data on your site, then you have introduced data drift right from the start.
The situations listed above can change both the amount and the type of data. Broadly speaking, data drift can be grouped into two types: class-conditional drift and class-balance drift.
Class-conditional drift
Class-conditional drift means that the content within a particular class changes. For example, a hacker may use a set of fake (stolen or artificial) mugshots to create fake profiles on a social platform. Let’s say an AI is trained to recognize these fake mugshots and deny profiles that are likely to be fake. Class-conditional drift in this case means that the hacker changes the set of fake mugshots they use. They are still of the type “fake mugshots,” and the hacker is still creating the same amount of spam profiles, but the type of fake mugshots has changed.
Class-balance drift
Class-balance drift means that one class becomes more common relative to how common it was during training. In the fake profile example, it means that the hacker increases or decreases the amount of fake profile creation attempts, thus changing the proportions of real and fake data, without changing how the fake mugshots are created.
In this post, we take a closer look at class-balance drift and discuss why content moderators should be worried about it.
Class-balance drift example explored via an email spam filter
Before we dive into the class-balance drift example, let’s set the scene.
You created a custom email spam filter for your organization. Using some machine learning method, you have trained a model that, given an email, outputs the probability of it being a spam email. Assuming the ML model is reasonably good, emails that are actually spam are typically assigned a higher probability than non-spam. Given such an ML model, the content moderator manager has the freedom to pick a decision threshold above which the emails are classified as “Spam” and forwarded to a spam folder. Otherwise, the email is classified as “OK” and delivered to the recipient.
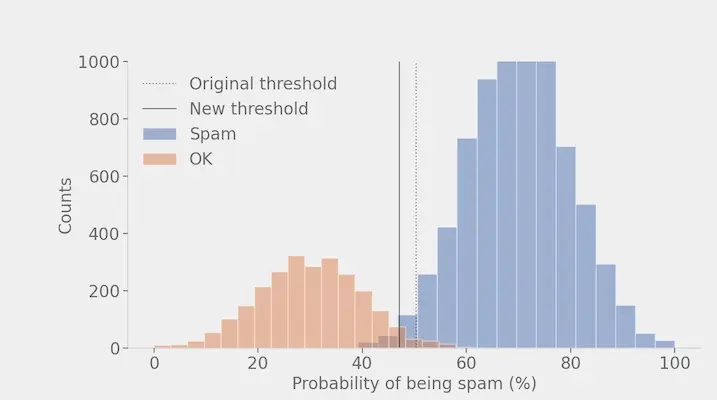
Below is some simulated data showing what this may look like. The blue bars represent emails that actually are Spam; the orange are emails that are OK. The figure, then, shows a histogram of the probability of being spam, as estimated by your model.

As is (very often) the case with machine learning, the bars overlap. This means that there is no way to get this 100% right. Inevitably, you will have both false positives: innocuous emails flagged as spam; and false negatives: spam emails that are not flagged as spam.
Working with the business teams, one typically assigns a cost to false positives vs. false negatives. It may, for example, be worse to flag innocuous emails than it is to let a spam email through. Or vice versa. Nevertheless, in this example, we will assume that the costs of both types are equal. Under such equal-cost scenarios, the goal of the content moderator is simply to minimize the total number of mistakes.
Using this toy data with 5,000 samples from each class, we calculate the optimal decision threshold to be 50.3%. This is calculated by sweeping over (trying) different thresholds and checking which one results in the fewest errors. In other words, given this distribution of probability of being spam, the best you can do in terms of minimizing errors is to classify any sample with probability of being spam above 50.3% as Spam.
With this threshold, we get 202 errors: 93 false positives and 109 false negatives. In total, the error rate is 202/10,000 = 2.0%.
The impact of class-balance drift on your email spam filter
Let’s say that, after our content moderation AI has been working consistently for some time, we are now starting to see much more spam on the platform. (In other words, you’re experiencing class-balance drift.) In fact, you are seeing three Spam messages for every OK message. How does that affect your goal of minimizing errors?
Using the same decision boundary as before, we get 238 errors: 49 false positives and 189 false negatives. So the error rate increased from around 2.0% to 2.4%, mostly due to a large increase in false negatives (i.e., an increase in the number of spam emails that are not flagged as spam). This increase in false negatives is expected since there is more spam to be misclassified.

How do I keep the false negative rate down when the amount of spam increases?
The good news is that there is a simple way to reduce the error rate and re-balance the types of errors. Using the same calibration method as before, we find a new optimal decision threshold of 47.9%. Using this new threshold, we see 179 errors: 82 false positives and 97 false negatives. That is an error rate reduction of (238-179)/238 = 25% simply by changing the decision threshold!
Note that we did not change the trained model. Nor did the type of spam change (the data is still drawn from the same distribution) – we just saw more of it! This is just one of many examples of how class-balance drift can negatively affect the efficacy of your moderation system and what you can do to remedy it.
But how do I even know that class-balance drift is happening?
There are several key indicators that a content moderator should keep track of in their data, their AI model, and among their human moderators. One of the key indicators within the data itself is the class balance over time. If there are big changes in class balance, suddenly or slowly over time, you should consider re-calibrating your confidence threshold as suggested above. If that doesn’t solve the problem, then you will need to look for class-conditional drift as well, or broaden your search within your content moderation system to your model and your human moderators.
Do you think you might be experiencing a data drift challenge but aren’t sure how to correct it? Reach out if you’d like to brainstorm solutions with a Nyckel co-founder.