Glossary of Computer Vision Function Types
Various types of computer vision can help you identify, categorize, and search among millions of images in just a few moments. Discover the most common types of computer vision.

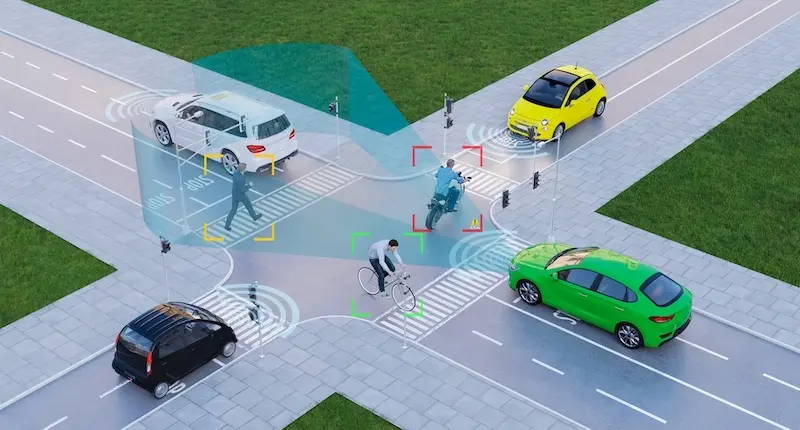
Computer vision refers to machine learning techniques used to understand and process image and video data. There are many types of computer vision with numerous practical applications. To give you a better understanding of computer vision, we define some of the most common types.
- Object detection: Object detection identifies the locations of certain objects in an image. Aside from finding the exact locations of objects, object detection is also frequently used to count the number of objects or to detect the presence or absence of an object. Typically, an object detector draws a rectangle, called a bounding box, around each targeted object that it finds. A less common but faster approach is for the object detector to just detect the center points of each object. For most applications, center detection can often give you all the information you need, allowing you to train and launch your model quicker than with bounding boxes.

- Image classification: Image classification categorizes images using predefined labels. One image classification example could be classifying images of street signs by labeling them with what type of sign they are: stop sign, yield sign, school zone, or pedestrian crossing. There are three types of image classification: binary classification, multi-class classification, and multi-label classification. In binary classification, the image can be labeled with one of two labels. In multi-class classification, an image can be labeled with one label of many possible choices. And in multi-label classification, an image can be labeled with multiple labels of many possible choices.
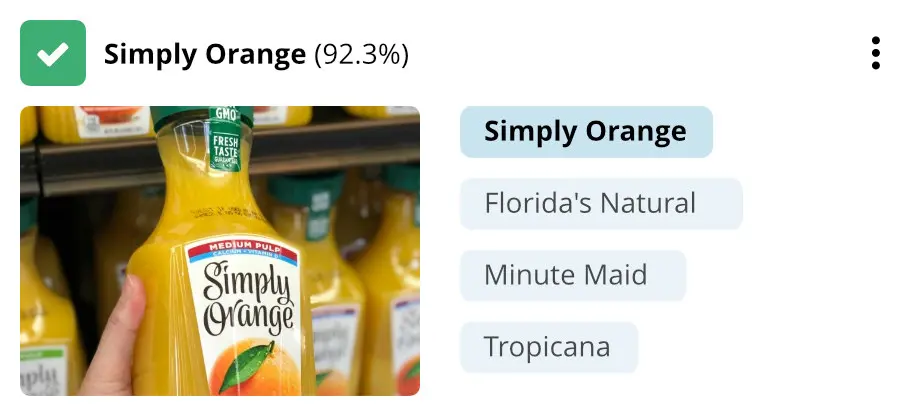
- Image tagging: Image tagging is another term that you can use to describe multi-label image classification. In image tagging, one image can be tagged with multiple labels. For example, if you have a photo of a dress that’s multiple colors, image tagging allows you to identify more than one color in the dress and tag it with all of the respective labels (e.g., green, red, and yellow).

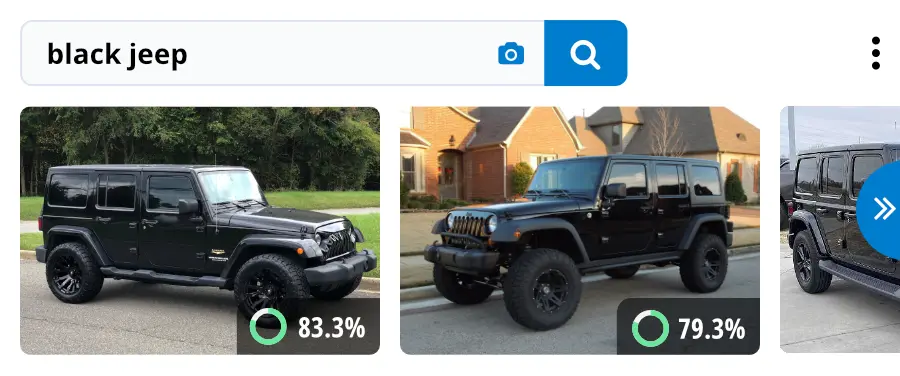
- Semantic image search: Semantic image search lets you use either an image or text string to search for a certain object within a gallery of images. For example, you can search “green dress” to find all of the green dresses within a database of images.
- Semantic segmentation: Semantic segmentation breaks down the pixels of an image to determine what each pixel is. It identifies all of the pixels in an image and then tags them based on what category (i.e., object) they are. Semantic segmentation is particularly important for self-driving cars. Self-driving cars need to be able to accurately identify the drivable surface. Semantic segmentation functions look at each pixel of an image to determine: Is this pixel part of the road? A pedestrian? A street sign? Tagging what’s in front of and around the car with these labels tells the car where it can and can’t drive.

- Instance segmentation: Instance segmentation is similar to object detection in that it identifies instances of objects within an image. Instead of drawing a box around the object or detecting its center, instance segmentation finds the precise pixels that correspond to that object. This additional precision comes at a cost. Training images need to be annotated in a similar manner, which is time-consuming. The training and inference process is also more computationally demanding and expensive as a result. But sometimes you need this additional precision. For example, when you want to remove a specific person from a photo while keeping the other people in it.

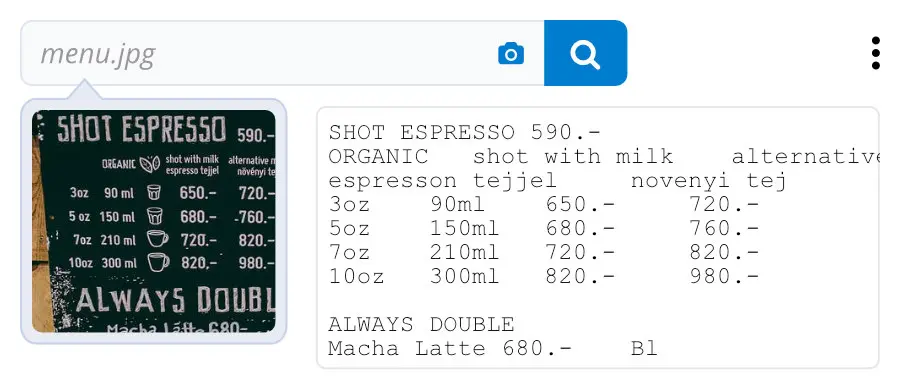
- Text extraction or optical character recognition (OCR): Text extraction or OCR converts an image of text into text that’s machine-readable. For example, you can scan a hard copy of a form and convert it into an editable text document using text extraction.
- Scene reconstruction: Scene reconstruction enables the function to “imagine” a visual that’s not actually in the image. For example, if someone in a photo is holding a balloon, the function can imagine what’s behind that balloon. Scene reconstruction can come in handy if you want to edit an object out of a photo but want to fill that blank space with what was behind it.

- Event detection: Event detection detects certain events that happen in video data. For example, you might want to know if someone appeared on your home security camera. Using event detection, you can determine at what point in the video a person stepped in and out of the frame.

- Object tracking: Object tracking can show you where an object is at each moment in a video and can track the path of that object. For example, you can use video tracking to track the movements of a basketball through each frame of a recorded basketball game. This applies object detection (see earlier bullet) to videos.
- Motion estimation, aka optical flow: Building on object tracking, motion estimation enables you to predict where an object is going to be in the future. A fun example of this is creating a basketball hoop that won’t let you miss because it predicts where the ball is going — and where the hoop needs to be — for you to make the basket.

- Pose estimation: Pose estimation detects human figures and understands their body pose. It is used for things like gesture detection and motion capture.

- 3D scene modeling: 3D scene modeling involves taking 2D photos of different walls within a room and asking the computer to reconstruct a 3D rendering. This is how companies like Matterport, a spatial data company, create 3D virtual tours of homes using photos of the house.

- Image restoration: Image restoration removes noise, damage, and other distortions from an image and makes adjustments to the image based on predictions of what its original color, lighting, and other factors would have been.
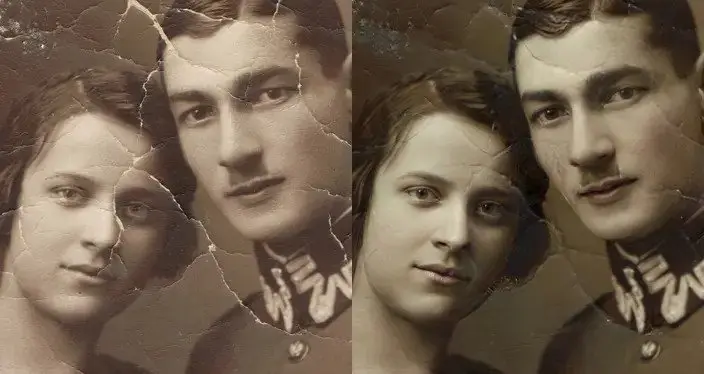
- Keypoint detection: Keypoint detection identifies and localizes different key object parts or “keypoints” within an object. For example, identifying noses, mouths, eyes and eyebrows as all being keypoints that constitute a human face. This is used for tasks such as face recognition and motion capture.

The science behind computer vision is complicated, but products like Nyckel make it accessible, even for companies that don’t have machine learning experts on staff. Take a look at our image classification, object detection, image semantic search, and OCR quickstarts to see how quick and easy it is to bring computer vision to your organization.
What other types of computer vision would you like to see defined in this glossary?
Reach out to feedback@nyckel.com.