Best practices for AI content moderation


So, your online community has a content moderation problem, and you have determined that you need a custom AI moderation process? Great – this tends to be the most powerful and flexible way to moderate content at scale! But how do you train a first model? And how to configure it? How should you integrate it into your moderation workflow? And how can you set up a dashboard to monitor the health of your system? This article outlines best practices for setting up a custom AI moderation system that stays on track and improves over time.
Initial training
The first move in setting up your AI integration is to select your training data, including examples of both good and inappropriate content. Note that this should be actual user-generated content (UGC) from your site – not public data that “seems relevant”. Next, upload your training data - pieces of images or text along with the desired output classification. The simplest classification applicable to content moderation is binary: “OK” or “Not OK” to post. Take care to make sure the classes are reasonably balanced – somewhere between a 50-50% and 20-80% split is ideal.
The next move is to train your model. You want to be able to assess its accuracy after you have trained it, and one way to do this is to keep aside some of your training data for this purpose – a so-called hold-out dataset. Another option is cross-validation [wiki], in which case you separate your training data into subsets which are used to train different models. The different models are then evaluated on subsets complementary to the ones they trained on.
Once the accuracy of your model is good enough to classify your data, you’re ready to move on to the integration.
Integration
The goal of AI-moderation integration isn’t to fully replace your manual moderation workforce. Instead, the goal is to minimize manual work over time while maintaining high quality moderation. There are two loops in the deployment phase: the moderation loop, and the monitoring loop. Both loops allow your model to continue to learn from new data.
The moderation loop is the most important, and the most obvious. It categorizes pieces of online content from your platform, thereby automatically moderating it, unless it cannot achieve a minimum level of confidence that you specify. These difficult cases are instead passed on to a human moderator who manually classifies them.
The monitoring loop is more subtle, but critically important in order to monitor the health of your data and your AI over time.
Let’s take a closer look at the moderation and monitoring loops next. After this, we will look at how to configure and monitor your system.
Moderation loop
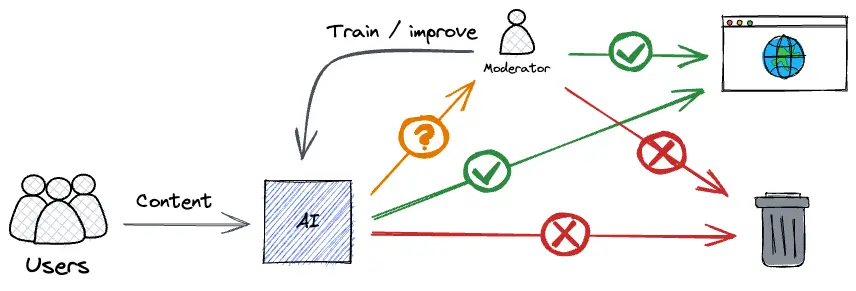
The primary purpose of this loop is to moderate content. As a side-benefit, it also improves the model. First, a piece of data is produced on the platform (by a user). The data is automatically classified by the trained model, which produces two outputs: a moderation decision (“OK” or “Not OK”), and a confidence score, e.g., 84% confidence.
If the classification confidence for a piece of data is above your chosen confidence threshold, then your implementation should act on what the model predicts for that piece of content. In other words, provided the threshold is met, if the model predicts “OK” then it should publish the content, and if the model predicts “Not OK”, then it should remove it.
In cases where the confidence threshold is not met, the implementation should send the piece of content for human review. Then the content and manual moderation decisions are fed back to the model by updating the training set.
Monitoring loop
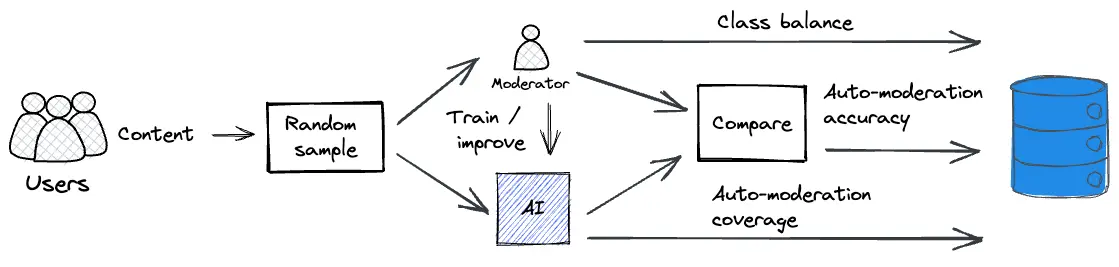
Because AI has a hard time dealing with so-called “data drift” – where the training data and implementation data are drawn from substantially different use cases – you cannot always rely on a model’s confidence scores. So, we need to have a way to pick up inaccurate confidence scores that arise due to data drift. To do this, we implement a monitoring loop, which is relatively straight-forward to do.
First, select a small random sample (e.g., 1%) of your UGC. The randomness of this selection helps to avoid any systematic bias. Next, send this data for both manual and AI moderation. From the resulting classifications, extract the following three key metrics.
From the manual classification, calculate and track the fraction of the data that belongs to each class. A sudden change in the number of false negatives or false positives, leading to a shift in the proportions of different manual classifications, is a type of data drift.
From the auto-moderation output, calculate and track the fraction that is above the confidence threshold (more on this below). This fraction should remain static or increase slightly over time. If it does not, you may need to re-calibrate the threshold.
By comparing the manual and automatic classification decisions, calculate and track the auto-moderation accuracy. It should improve. If it does not improve, then the type of data your model is receiving has changed – again suggesting data drift. In this case you will need to re-train your model.
Finally, feed the data, together with the manual decisions, back to the model so that it can improve. Given that the Moderation loop has picked out the “difficult” samples – those that are most informative for the AI to learn from – it might seem unintuitive to also include randomly sampled data. Adding difficult samples is indeed the basic premise of so-called active learning which has been studied extensively in the machine learning literature. However, using only difficult samples can impact the training and introduce data drift. Balancing the difficult samples with roughly the same amount of random samples creates a more robust training set for the AI.
Configuration
To configure your model, you need to determine the auto-moderation threshold (the level of confidence below which the model sends a piece of content for human review), and the random inspection fraction (the portion of automatically decided / moderated content which you double-check manually). Let’s take a close look at how you set these parameters.
Setting The Auto-Moderation Threshold
The most important parameter to configure is the auto-moderation threshold. To do this, you first need to work with the business department to make judgments about these three “costs”:
- How much does it cost to manually moderate content?
- What is the cost of erroneously publishing “bad” content, e.g., hate speech, nudity, or harmful or disturbing content (false positives)?
- What is the cost of erroneously not publishing “good” content, i.e., silencing legitimate community engagement (false negatives)?
To keep thing simple, we will assume that the latter two costs are equal. In this situation, selecting the auto-moderation threshold boils down to a trade-off between auto-moderation accuracy (since classification errors incur “costs” associated with false positives and negatives) and the auto-moderation coverage (since content that needs manual review incurs labor costs). To do this, follow the following pseudo code:
INPUT: a random set of sample
For confidence thresholds between 0% and 100%:
Create a filtered set of samples where the prediction is above the confidence threshold.
Store auto-moderation coverage (length of filtered set / length of full set)
Store auto-moderation accuracy (the AI - human agreement within the filtered set)
OUTPUT: Lists of auto-moderation coverage and accuracy
Below is a trade-off plot thus created for a Nyckel text classification function trained on the SurgeAI toxicity benchmark. So, for example, this classifier can auto-moderate 89% of the entries at 96% accuracy. Or 78% at 97.8%.

The best operating point, i.e., the right trade-off between accuracy and coverage, is determined by business costs.
Over time, this curve will move further up and right, meaning that the accuracy achieved at a given proportion of coverage becomes higher. For example, here we overlay a training subset with only 100 samples taken from the same dataset:

So for example, at 96% accuracy, the auto-moderation coverage increased from around 80% to 90% in this experiment.
Setting The Random Inspection Fraction
The other parameter to set is the fraction of samples that are randomly selected. The main rule here is that as long as things are proceeding “as expected”, we can lower this slowly but surely.
As soon as we see something unexpected in the monitors (next section) we probably want to elevate this fraction again. A typical initial value for a new AI implementation is 0.1–1%.
Dashboard
Machine learning works best when the data you deploy the model on (i.e., the ongoing stream of UGC that the model must classify) is “similar” in a statistical sense to the data you trained on.
For example, if your company launches in a new demographic or region, they may see new types of content on the site. This new content may adversely influence the accuracy of the ML model, requiring the company to adjust the appropriate parameters: auto-moderation threshold and / or inspection fraction. But changes in accuracy may also be caused by users gaming the rules that you’ve put in place, or by human moderators becoming fatigued.
In order to pick up and distinguish between such changes in the data, it is important to keep an eye on a few key metrics across the three main components of your system: the data, the AI and the human moderators themselves. As a general rule, any of these metrics may change gradually. Alerts should therefore be triggered against a baseline rather than, say, last week’s numbers.

Monitor the data
First of all, we need to monitor the data (i.e., the UGC) being moderated. There are two key metrics to consider here: the data volume, and the class balance (i.e. the relative amount of UGC of each class). Since we’re trying to monitor the consistency of the UGC itself, this should be calculated from high-quality human inspection of actual data – not from AI predictions. Specifically, it should come from the monitoring loop.
What to do if the data changes?
Any major change in these two metrics indicates that the data has “drifted” somehow and that we are now effectively seeing new types of content. If we see a two-fold increase in content creation, it may, for example, suggest that some world event happened that people are talking about. Such world events could drive a change in the tone or content as well; terrorist attacks may, for example, fuel racist remarks against certain minorities or religions. If we see a shift in the amount of content flagged as “violent”, “sexual”, or any other type of breach of community standards, then this also suggests that “something happened”, either with your user-community or in the world at large.
When you detect a change in the volume or class distribution of your UGC, the first thing to do is to look at the data to identify the new content and decide whether / how to adjust your moderation policies. Next, we train human moderators to enforce the (possibly augmented) policy on the new data. Finally, you can use your human-moderated sample to re-train and re-calibrate the AI moderator to handle new data correctly.
Monitor the AI
Second of all, we need to make sure that our auto-moderator continuously improves, or at least that it doesn’t degrade. This requires monitoring two metrics: auto-moderation accuracy, and auto-moderation coverage. Measure both of these regularly and track them over time.
Accuracy is simply the fraction of correctly classified data. This should be measured on data from the monitoring loop.
If you are following the best practices outlined in this article, you only auto-curate content above a particular threshold of confidence. For example, you may have decided to manually review anything that the AI moderator is less than 80% confident about. The fraction of content that is auto-moderated is sometimes called “coverage”.
What to do if you see a drop in AI performance?
Auto-moderation accuracy and coverage should both increase over time. If they do not, one of two things could be happening: either your AI train-and-deploy pipeline is broken, or the content on your online platform has changed in character to the point where the AI is no longer correctly trained to handle it.
If you determine that your train-and-deploy pipeline is broken, you are in luck. Simply getting it up and running again should fix the problem. If you determine that there has been some data drift in your UGC, then you will need to re-train the AI using recent content vetted by human moderators. Depending on business costs, it could be prudent to adjust the confidence threshold to be more conservative at this point, balancing accuracy vs coverage in a way that relies on greater human involvement in the short term.
Monitor the Moderators
The third thing to monitor in your content moderation AI integration is a core component of your content moderation team: the human moderators. To do this, send a subset of the data to multiple (e.g., at least 5) moderators. Assume that the most common answer is correct and, for each moderator, monitor the fraction agreed: the fraction of decisions that agrees with the majority vote decision. Plot this agreement fraction over time for each moderator.
Be mindful about the ethical and legal implications of this kind of sampling practice. By collecting and comparing performance data, and effectively using employees to monitor each others’ performance, albeit in a distributed way, you are setting up a culture of surveillance with data protection implications. There may be nothing wrong with this in principle, but the onus is on the system designer and the HR department to be transparent about what’s going on in the workflow; no one likes to find out by accident that an algorithm is secretly monitoring their performance – especially after a long day of screening toxic content.
What to do if your human moderators are inconsistent?
Your content moderation AI integration system assumes that your human moderators are making 100% of their decisions absolutely consistently in line with policy. In reality, people get tired, have bad days, misunderstand community standards, have learning curves for policy updates, become fatigued, and have more cognitive biases than you can shake a stick at.
If the agreement with majority vote changes significantly over time for any particular moderator, then it could suggest that they have become demotivated or need more training.
If the agreement for the whole group decreases over time, it may suggest that the instructions are poor and / or that the content has changed. You may need to revise the moderation policy and run workshops to talk through corner cases.
Conclusion: Best practices for AI content moderation
The key to AI content moderation is to train your model with good data, and set up routines to monitor and optimize your model’s performance.
Set up your model with real data, partitioned into a training and test set or use cross-validation. Configure your model based on the balance of business costs, i.e., the labor for manual moderation, and the reputational costs of false positives and negatives.
Keep an eye on your coverage vs accuracy, and look out for changes in the accuracy of confidence estimations. If you suspect data drift, sample some new training data, annotate it, and see if this brings the accuracy back up.
Integrating an AI is not a one-off process. But, with good practices for set-up and deployment, it becomes a self-improving moderation system that drives cost savings and efficiency for your organization. Get started today with Nyckel!