Introducing Invoke Capture - Automatically Gather Important Data to Improve Your Model

At Nyckel, our goal is to give you the tools to keep your data fresh, correct, and up-to-date. To this end, we are excited to introduce our newest feature: invoke capture – active learning on model invoke data.
The problem
Initial training is only the first step in the lifecycle of a machine learning model. To make your model more robust and keep it robust, you’ll want to continue to add more training data. Here are a couple of reasons why:
- The world is always changing, and so is the data that your model encounters. This is called data drift, and training data needs to be continuously updated to account for it.
- We make it possible to spin up a model with a small amount of training data — as few as two examples per label — with impressive accuracy. While our customers love how this gets them started quickly, we strongly encourage adding more data over time to make the model more robust.
But where do you find data to add to your model? And once you have data, how do you find the important subset of data to focus your annotation effort on — the data that is most likely to improve the model?
The solution: Intelligently capture data as you invoke your model
The best place to find more data is through the samples your model encounters as it is invoked. With invoke capture, Nyckel automatically and intelligently captures informative data as you invoke your models and then places it in a queue for your team to review and annotate later. When capturing data, we try only to capture important data. For example, data where the model is not confident, data from rare classes, etc. This process is commonly referred to as “active learning.” As you annotate this data in Nyckel’s dashboard, we retrain and redeploy your improved model.
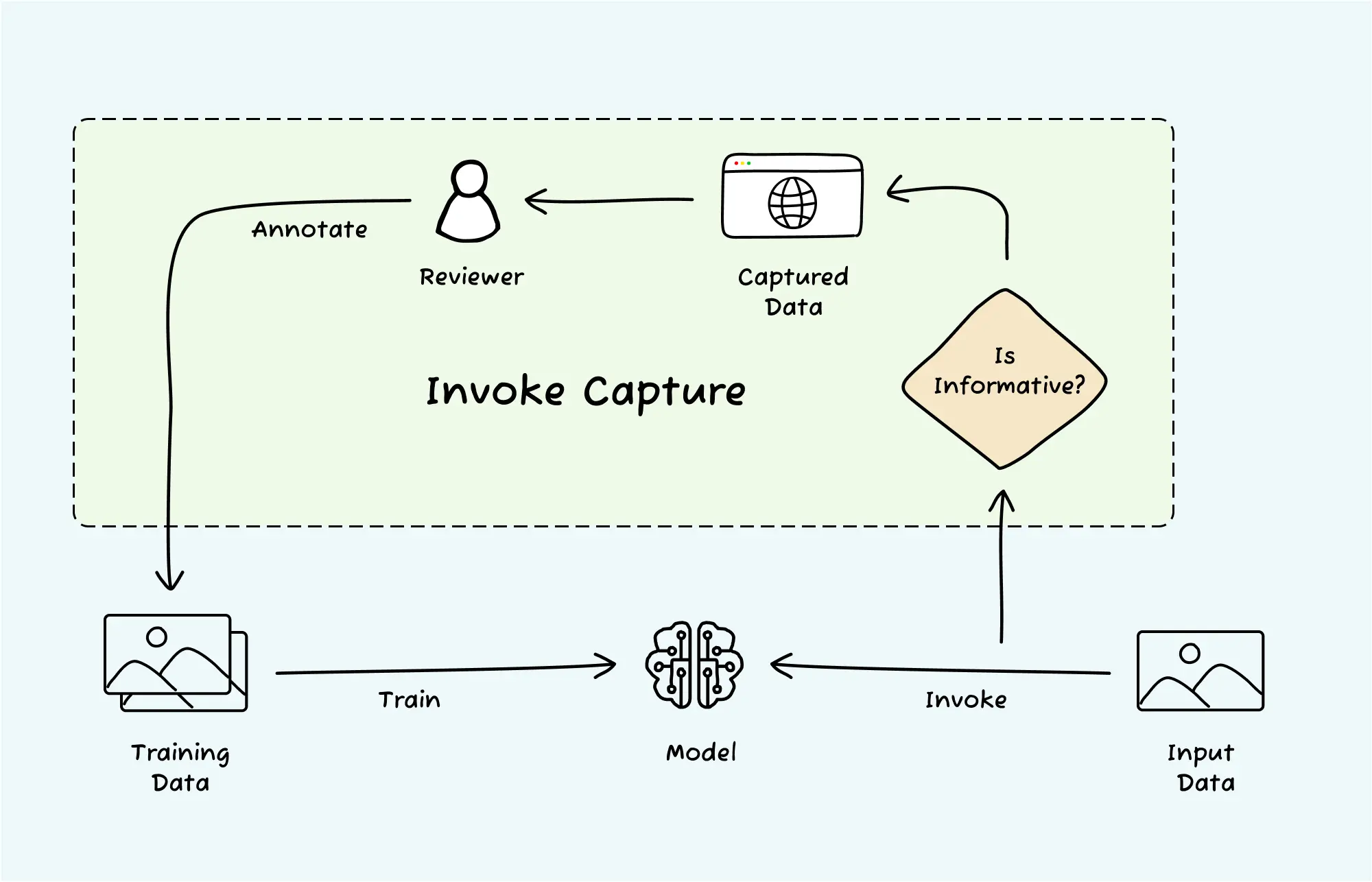
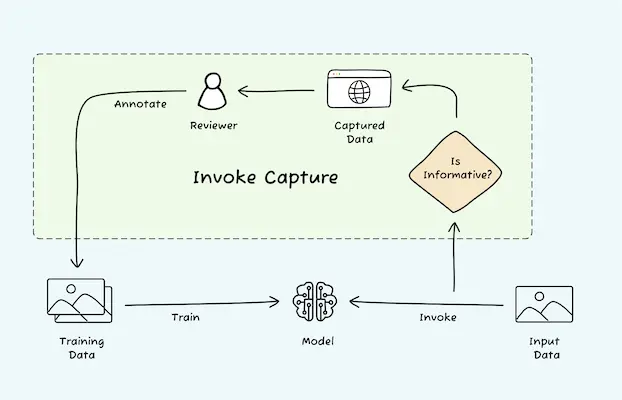
How does it work?
Invoke capture is a key element of our end-to-end ML offering. It’s a built-in data flywheel powered by our active learning system. Here is how it works:
- Call your trained model using the standard
/invokeendpoint. - Nyckel automatically checks each data sample (image, text, etc.).
- Samples that look “informative” are added to a staging area. You can find this staging area in the “Capture” tab on Nyckel’s dashboard.
- Users annotate samples in the staging area at their own convenience.
- Annotated samples are automatically added to the training data.
- Nyckel retrains and redeploys the improved model.

How do we decide which samples to capture?
Identifying which samples to capture for annotation is not trivial. (Refer to our deep dive on the various methods you can use to capture informative data). For Nyckel’s automated invoke capture, we use several strategies for capturing informative data, including:
| Sample type | Motivation |
|---|---|
| Low-confidence samples | These are samples where the model is uncertain about the prediction. |
| Random samples* | Useful to avoid data drift and to get an unbiased measure of accuracy. |
| Samples from rare classes | Improve performance of rare classes. Help balance out the training data. |
| … | We’ll continue to add new sample types over time. |
*It may sound counter-intuitive to include random samples, but balancing the training data with randomly sampled data is important to ensure the model generalizes to new types of data.
Over time, we will add to and improve our capture strategies.
Why is invoke capture important?
To reiterate what we said earlier, a machine learning model exposed to real-world data is never fully trained. Data changes over time, and new corner cases will always pop up. Selecting and annotating more data is, therefore, critical for a healthy ML production system.
However, most data tends to be very boring and adds little value to the training set. So, if you rely simply on annotating randomly here and there, you will never discover the corner cases and data issues. This is where “active learning” shines. It helps you focus your valuable annotation time on the samples that matter the most to improving your model.
We are excited to see you use this new feature and provide feedback. We are particularly excited about how this enables you to train and deploy a model with very little data and then continuously improve your model by periodically visiting Nyckel’s dashboard and annotating some captured data.
Invoke capture is currently in beta. If you’re interested in trying it or have any questions about the feature, reach out to us at any time.