How Reddit Could Use Machine Learning to Better Moderate Subreddits


Subreddit moderators don’t have an easy job. These are the hard-working people who lock down comments when they’re getting overly contentious, block NSFW content, and reject posts for straying from community guidelines, like a fence striking its way across the landscape in a picture posted in r/EarthPorn.
EarthPorn: The subreddit for gorgeous images of nature (that at least appear to be) untouched by the human hand.
Recently, NewScientist reported that “Reddit moderators do $3.4 million worth of unpaid work each year.” These volunteer mods are doing content moderation work for free, simply for the love of their passions.
But surely machine learning (ML) can tell a fence from a backdrop of nature? Couldn’t Reddit be deploying ML to do this type of content moderation instead? We decided to experiment with Nyckel to see how quickly we could train an image classification system to moderate r/EarthPorn images effectively.
[For text moderation as opposed to images, take a look at how Nyckel helped Gust stop spam and allowed Taimi to auto-moderate their social network.]
Our starting point: Moderation rules for r/EarthPorn
There are a few community guidelines for posting in r/EarthPorn, but a core guideline that we can assess from a machine learning moderation point of view, is:
No images with human-made objects, people or animals.
For simplification for our demo, we are shortening this to “no images with human-made objects.” More rules can always be added later.
Let’s test to validate our auto-moderation idea.
Step 1: Crawl the r/EarthPorn subreddit for the ‘Good’ data
To get the ‘Good’ data, let’s retrieve the moderated content from r/EarthPorn. We’ll want between 25 to 50 varied images.
Rather than building a custom scraper, we’re using Clarity Coders RedditImageScraper on GitHub, which has a YouTube walkthrough and uses Reddit’s Python API Wrapper. Instead of running the scraper with a Reddit web app as suggested, we changed it to a personal use script, using a throwaway account’s credentials to scrape the images, which are then delivered neatly to the /images folder.
Tip: Once you have a list of images, you might need to clean this data by deleting any images where you find man-made objects the mods may have missed.
Step 2: Search the web for the ‘Bad’ data
We won’t be able to crawl EarthPorn for rejected images, but we still need to find some ‘Bad’ data to train the model. For instance, here is an example of an image that got blocked as it had a man-made structure (a bridge) in it.
We will need to find other nature images that contain some man-made structures (e.g., road, bridge, building, power line, tower), making sure the images are varied, both in the type of nature and the type of man-made structure. Again, this will require around 25-50 such images.
Step 3: Train a Nyckel image classification function to tell if an image has man-made structures or not
Using the images we found in Steps 1 and 2, we can train a Nyckel classification function by assigning labels to both the ‘Good’ and ‘Bad’ images. Then, we simply invoke the function with a new image to see whether it is a picture of nature without a man-made structure in it.
Try it for yourself with this clickable demo:
Is the function accurate enough yet to accurately approve or reject any image we give it? Probably not. However, human moderators can help train the model with each image rejection and approval.
How it could work in the real world: Embedding image classification in moderator workflows
Our example above shows how to classify the images from r/EarthPorn retrospectively. However, this process could be embedded in the subreddit moderation workflow with Custom AI-Assisted Content Moderation.
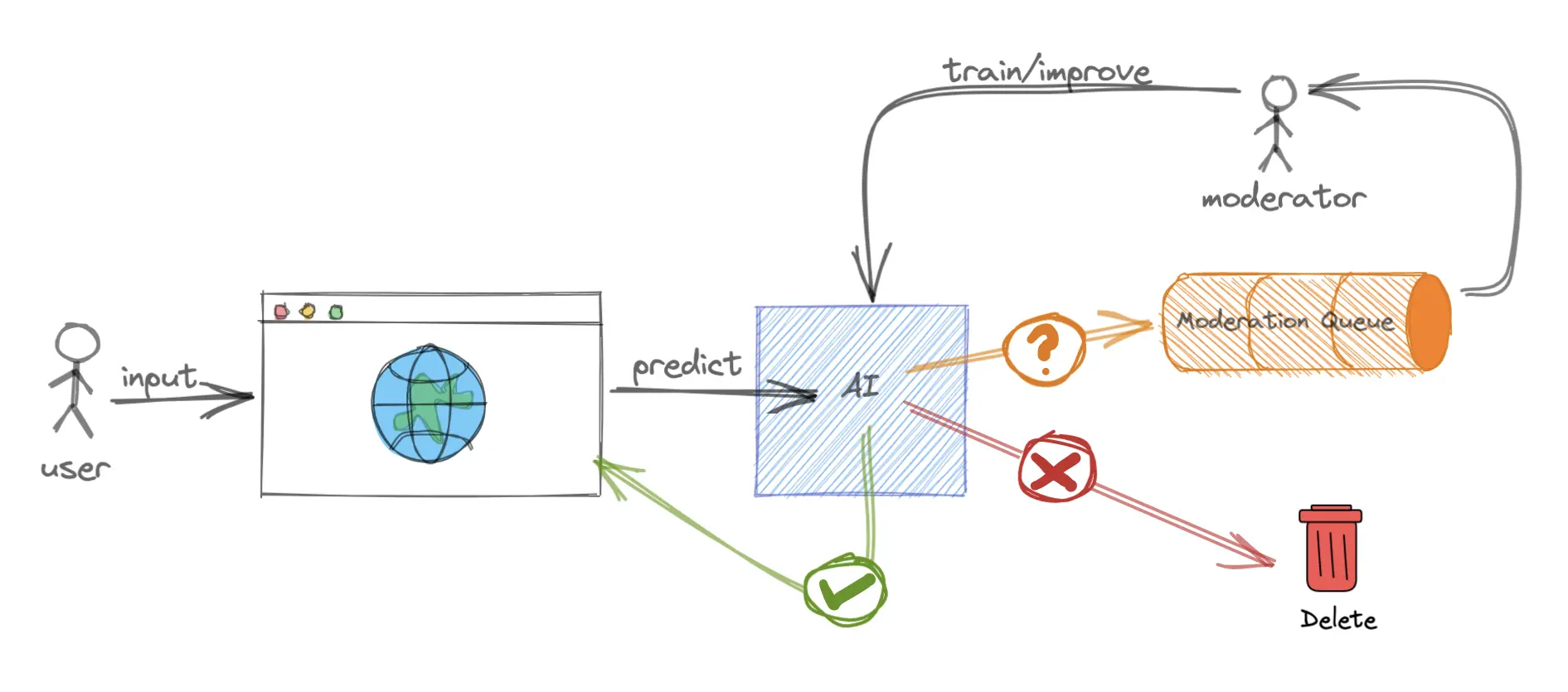
Each time a moderator manually approves or disapproves a post, the image and its approval or disapproval tag is routed to Nyckel via the API, so AI-assisted moderation gets more accurate with each manual action.
By giving moderators a list sorted by confidence (lowest to highest), moderators can approve or disapprove the most difficult classifications first, in a priority system which will not only help save time but improve the AI model.
When the AI reaches a high degree of accuracy, after 100 or so photos, then it can be trusted to auto-approve or reject submissions that have the highest confidence.
Auto-moderation is essential for any social platform
If you’re running a social platform, moderation is essential. While Reddit is using auto-moderation, its AutoModerator system doesn’t do much ML, and there is no tailoring to the rules of a subreddit. Instead of using volunteers to do the majority of the work, it should be ML augmented by humans.
With simple auto-mod systems like we made with Nyckel that learn with each mod’s approval or disapproval, those unpaid volunteers will have a whole lot more time on their hands to enjoy the subreddit they’re so passionate about. Plus, Nyckel has a custom content moderation API to boot.
Interested in giving Nyckel a spin yourself? Sign up for a free account at any time, and reach out to us with any questions.