


"We are very impressed with Nyckel's API-based hosting approach. It was simple to turn our idea into a reality."
— CTO, LinkedClinet


"We are very impressed with Nyckel's API-based hosting approach. It was simple to turn our idea into a reality."
— CTO, LinkedClinet

We turn your model into a simple API endpoint, with integrations to common data platforms. Leave the heavy lifting of GPU management, cost optimization, scaling, and failure handling to us.
We optimize your model and hardware choice for cost per inference, then deploy close to your data to eliminate insidious data transfer fees. Process petabytes of data with clear per-inference pricing and no infrastructure headaches.
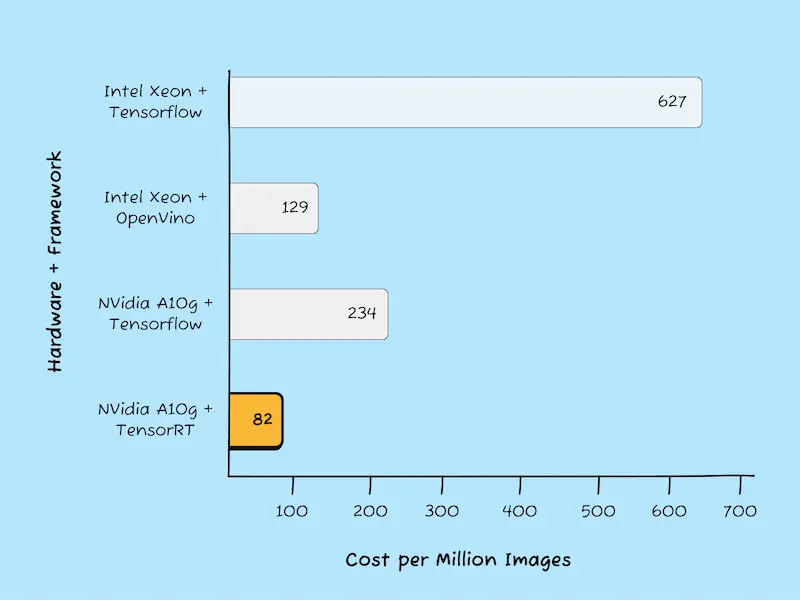
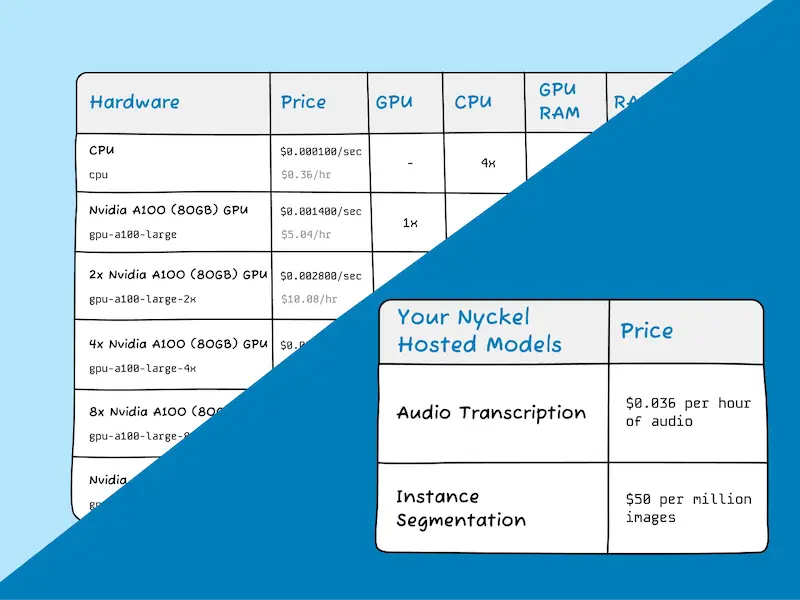
Tired of the guesswork around per-second GPU pricing? We price per inference unit so you know exactly how much you're going to pay.
Deploy your model on our secure infrastructure in any AWS, GCP, or Azure region. Or deploy in your cloud so your data never leaves your network.

| Model | Use | Price | Comparison |
|---|---|---|---|
| Whisper-V3-Large | Audio transcription | $0.036 per hour of audio | 10x cheaper than OpenAI |
| MaskRCNN | Image segmentation | $0.052 per 1k images | 3x cheaper than Pytorch on GPU |
| FasterRCNN | Image object detection | $0.048 per 1k images | 3x cheaper than Pytorch on GPU |
| Multilingual-e5-large | Text embeddings | $0.05 per 1M tokens | 2x cheaper than DeepInfra API |