Introducing Multimodal Classification

Nyckel is proud to announce the launch of a new function type: multimodal classification.
Classification models are generally built around a single input type: videos, images, text, data, etc. With Nyckel’s new multimodal function type, you can build a model that accepts both text and image inputs.
One example involves product categorization. With multimodal classification, you can ingest both the image and its metadata to classify the SKU into predefined categories.
In the below visual, for example, the multimodal function uses both a picture and metadata to add a new tag to the product. Neither the image nor the text alone would suffice here, as
- The text points out what clothing item to look for, but doesn’t give gender
- The image includes multiple clothing types
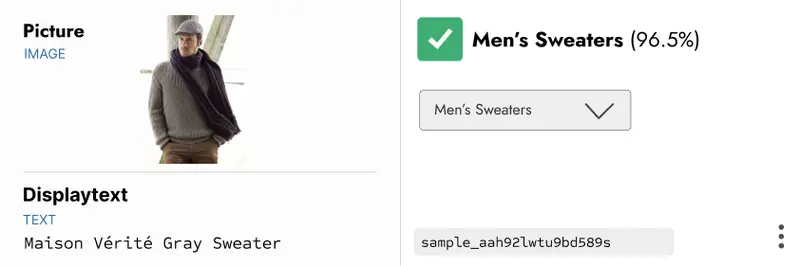
By using both the product’s image and its metadata text, this retailer is able to submit SKU information and have the model tag it appropriately.
Another example involves digital asset management (DAM). These tools make it easy to store and search images by tags. But the actual tagging of those photos can be manual and tedious. An auto-tagging classification model (whether text or images) would certainly streamline the process.
The problem here is that relying on an image or text classifier alone may not be enough to tag assets as you would like.
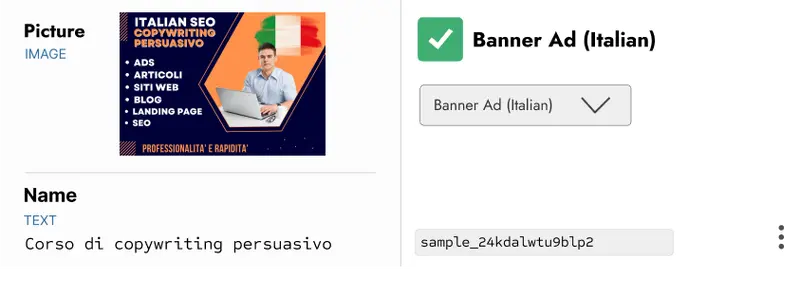
Let’s say you’re a marketer using a DAM to house your assets, and you’d like to tag them by language and type, such as, “Banner Ad (English)” or “Sales Collateral (Italian)”.
Currently, neither metadata is attached, although each asset’s name is written in the respective language, and the cover image makes it obvious what it is. Relying on text or image classification alone wouldn’t suffice here, as:
- A language classifier could tell you the language, but not the content type
- An image classifier wouldn’t typically be able to infer the language of text in the image.
Multimodal tagging addresses this problem. Here, you could pass both the cover image and the asset name, and the modal would tag it according to your rules.
Training your own custom Multimodal Classification or Tagging function is easy with Nyckel.
This new function type adds to Nyckel’s suite of models, including multiclass and multilabel classification, image and text search, OCR, box detection, and center detection.
If you’re interested in learning more about multimodal classification, reach out here.