Image Classification Benchmark: Google, AWS, Hugging Face & Nyckel

Every day it seems there are more options for training and deploying image classification machine learning models. Choosing the best solution for your particular problem comes down to what matters most to you:
- Training Speed: Are you experimenting, frequently training models, or retraining models with new data? If so, you will probably want to train and deploy models quickly.
- Model Accuracy: Is your aim to deliver the highest level of accuracy in your deployed model? Do you only have small amounts of labeled data and want to maximize model accuracy with what you have?
- Latency and Throughput: Are you expecting low latency and/or high throughput when invoking your deployed model, whether through a single request or concurrent requests?
- Developer Experience: If you think your developer time and happiness is valuable, which you probably do, you’ll want a fast and painless developer experience and a product built with this in mind. If you don’t have ML experts on your team, you’ll want a product that doesn’t assume ML expertise.
In this image classification benchmark, we test four machine learning services on image classification tasks to see how each stacks up. To do so, we trained over 100 models on 273,280 images across 7 datasets and 4 machine learning services, so we could test the performance of each service across different datasets and training set sizes. Let’s look at what we found!

Table of Contents
- Table of Contents
- Methodology
- Training Times
- Accuracy
- Latency and Throughput
- Developer Experience
- Pricing
- Wrapping up
Methodology
You can read more about the exact methodology we used and use that code to run these same experiments. (Note: training/invoking models on these services incurs costs. See our section on pricing below for more on this.)
We tested four different machine learning services that provide training and deployment of image classification models:
Each ML service was used either through an API, the product’s online UI, or a combination of both. We ran each of these datasets through the services:
- Stanford CARS dataset
- food101 dataset
- Oxford-IIIT Pets dataset
- Intel Image Classification dataset
- beans dataset
- Clothing1M dataset
- Chest X-Ray Images dataset

Depending on the size of the dataset, models were trained with 5, 20, 80, 320, and 1280 images per class. This is called ablation and is used to understand how the model performs with various amounts of training data.
| Dataset | Classes | Ablations |
|---|---|---|
| Stanford CARS | 196 | 5, 20 |
| food101 | 101 | 5, 20, 80, 320 |
| Oxford-IIIT Pets | 37 | 5, 20, 80 |
| Intel Image Classification | 6 | 5, 20, 80, 320, 1280 |
| Beans | 3 | 5, 20, 80, 320 |
| Clothing1M | 14 | 5, 20, 80, 320, 1280 |
| Chest X-Ray | 2 | 5, 20, 80, 320, 1280 |
With the exception of Nyckel Image Classification, which uses cross-validation, 20% of each training set was used for validation. For example, with the Stanford Cars dataset:
- For the ‘5’ ablation, four images per class were used for training with Google Vertex, AWS Rekognition, and Hugging Face AutoTrain, and one image per class was used for validation. With Nyckel Image Classification, all five images per class were in the training set, and the service performed cross validation with that set.
- For the ‘20’ ablation, 16 images per class were used for training with Google Vertex, AWS Rekognition, and Hugging Face AutoTrain, and four images per class were used for validation. With Nyckel Image Classification, all 20 images per class were in the training set, and the service performed cross validation with that set.
Training and validation sets were cumulative, so the training data in the ‘5’ ablation was also included in the training data for the ‘20’ ablation, and so on. The same for the validation set.
Testing was performed by invoking the inference endpoint on the entire testing set supplied with the dataset.
We measured:
- Time taken to train each model
- Accuracy over the entire testing set
- Latency of each model invoke
- Throughput with 10 concurrent model invokes
Training Times
Here is a bar graph showing the training times (on a log scale) for the largest ablation in each dataset for each service:

Nyckel Image Classification trained models quickest, over all dataset sizes. The service always trained models within seconds of the final image upload. Nyckel trained at least an order of magnitude faster than the next fastest training service, Hugging Face Autotrain, and 2-3 orders of magnitude (100-1000x) faster than the slowest service, AWS Rekognition.
Why are we measuring training times when most ML benchmarks focus just on model accuracy? Is it just to make ourselves look good?
Imagine you are coding, and your build takes hours - that would be maddening! We feel the same way when ML training takes hours. More than just reducing frustration, we think faster training can have massive positive effects on your ML workflow - it encourages you to experiment, make and recover from mistakes, and continuously improve models. We take these things for granted in the software development life cycle, so we’re working hard to bring them to the ML development life cycle.
Hugging Face AutoTrain models usually train between 2 and 10 minutes, with the exception of the two largest dataset-ablation combinations, the food101 320-images-per-class ablation and clothing1M 1280-images-per-class ablation. These took just over one hour, and 20 minutes, respectively.
The training time for both AWS Rekognition and Google Vertex was measured in hours. However, Google Vertex AI training timings were extremely consistent, coming in almost always at just over the two-hour mark.

The graph above shows training time as a function of the size of the training set. The smallest dataset-ablation combination always trained faster for AWS Rekognition, Nyckel Image Classification, and Hugging Face AutoTrain, but not for Google Vertex AI. This suggests that Google Vertex might not be ‘training’ for the entire 2 hours, but rather queueing the training in a pipeline or performing some other processing during this time.
Though consistency is helpful in mapping out a pipeline, quicker training will almost always be more helpful, especially during a prototyping phase. If you are experimenting frequently and want to try multiple models, having models ready in seconds or minutes is very different from waiting hours per training.
The same is true for models that are updated with new data frequently. If you are consistently feeding new data into your models and retraining, the ability to use that model again in seconds is a massive benefit.
Takeaway
Choose Nyckel Image Classification for the fastest training times and the ability to experiment and iterate quickly. Hugging Face AutoTrain is also good if quick training times are an important factor.
Accuracy
Of course, we measure model accuracy when benchmarking ML. Specifically for Nyckel, some are in disbelief at how quickly we train models and think “surely, I’m giving up some accuracy in exchange.” We want to show that **you can have fast training without sacrificing model accuracy**.
Accuracy is the fundamental measurement of a machine learning algorithm. If your models can’t classify images accurately, you may as well toss a digital coin for your predictions.
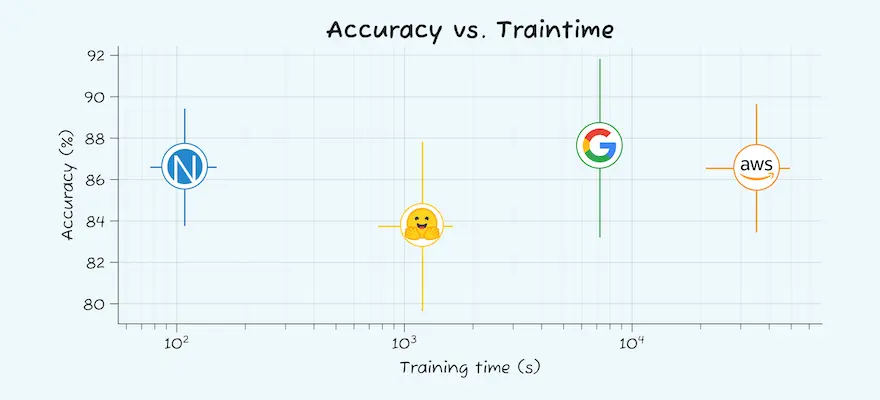
Here is a bar graph showing the accuracy for the largest ablation in each dataset for each service:

There is consistency across the services for most datasets. For the Clothing1M dataset, the accuracies are within 1-2% of each other. The same consistency is seen in the Oxford-IIIT Pets, Intel Image Classification, and Beans datasets for these largest ablations — all services performed comparably.
In the food101, Stanford CARS, and Chest X-Ray datasets, there was more variability. In the food101 and Stanford CARS datasets, three of the four services were consistent, with one (Google Vertex AI and Hugging Face AutoTrain, respectively) in each performing poorly. For some reason for these two datasets at the largest ablations, these models didn’t train well. In a real-life scenario, you might have luck tweaking parameters or the training set in situations like this and end up with consistent results.
The Chest X-Ray dataset did see variability across all four services. There is a quirk to this dataset where the data was divided into two classes, but three classes are actually present. This might have caused the problems, but the training data was the same across each service, so the well-performing Google Vertex AI model got exactly the same quirky data as the poorer performing Hugging Face AutoTrain model.
Ablation
An **ablation study** examines the accuracy of the model with different amounts of training data. This is a way of measuring how well each service performs with small and medium amounts of labeled data. We care about this because most of our customers start off with just a few labeled data points. We want to provide excellent performance with small amounts of data, with continous improvements as they add more.
Accuracy and model training depends on both the quality and the quantity of the data. The datasets we’ve used for this image classification benchmark all contain high-quality data, so our ablations are chosen to limit the data each service and algorithm has access to for training purposes. In theory, lower accuracies should be seen with less data. This also allows us to test how well each service does with small amounts of data and how their performance improves as more data is added.

In practice, we saw what we expected: lower accuracy with less data. Nyckel Image Classification provided the most accurate predictions with the smallest datasets. For the smallest training set, with only 5 images per class, it was able to average 73% accuracy. However, the variability between datasets was large at this ablation size. For instance, each service had an accuracy of ~75% for the beans and x-rays datasets, but only ~25% for the Clothing1M dataset at the smallest ablation (with the exception of Nyckel Image Classification with an accuracy on Clothing1M 5-images-per-class ablation of ~45%).
Hugging Face AutoTrain had the overall lowest accuracy for the smallest ablation, though this was primarily due to an extremely poor model of the Stanford CARS dataset.
As the ablation size increased, accuracy increased and variability decreased. Nyckel Image Classification continued to outperform other services when under 100 images per class were used in training. At the higher quantities of data, some services saw a decline in average accuracy. This could be due to two reasons:
- Some of the larger datasets (such as the food101 dataset and the Clothing1M dataset) had a high number of classes to predict, so average accuracy is likely to be lower.
- The Chest X-Ray dataset had the quirk where the data was divided into two classes, but three classes are actually present.
If we breakdown the data by dataset, we can see how each service performed:

Here we can see some of the characteristics of each service:
- Nyckel Image Classification performed well with the smallest ablations, being the most accurate with four of the seven datasets, and consistent with the other three.
- Hugging Face AutoTrain performed generally well overall, but was let down by a couple of poorly performing models.
- Google Vertex AI always performed well for the largest ablations.
- AWS Rekognition was consistent, but never the best option.
An important point to make: the training times discussed in the previous section have had no bearing on the eventual accuracies!
Takeaway
If you have limited data, Nyckel Image Classification is the best option for good predictive accuracy. If you have larger datasets, all services perform well, with Google Vertex AI marginally the best option, but the differences are less noticeable at that point.
Latency and Throughput
The ultimate users of these models will be your customers, and they’ll consume them via a real-time inference endpoint. You want your models to not just be accurate, but to return those accurate results to your customers quickly.
Thus latency, how long it takes for each request to the model to return with a prediction, matters. In this, Hugging Face AutoTrain and AWS Rekognition were the winners:

AWS Rekognition was faster than all other services, with a median response time of 167 ms. The next closest was Hugging Face AutoTrain with 190 ms, then Google Vertex AI with 467 ms, and then Nyckel Image Classification with 474 ms.
This means you can invoke the AWS Rekognition inference endpoint almost 3 times by the time the Nyckel Image Classification endpoint has returned. Variability was also highest with Nyckel Image Classification, with a ~0.5-second latency difference between the 1.5*IQR whiskers.
For one-off predictions for customers, all these latencies are fine. But often, customers want concurrent predictions of data. If we were running predictions serially, the difference between the median response for 1000 predictions to AWS Rekognition and Nyckel Image Classification would be about 5 minutes.
More likely, though, is that inference calls will be made concurrently. To test this, we called the endpoint for the same model (food-80) 1000 times using 10 concurrent connections. In this scenario, Hugging Face AutoTrain was the quickest, closely followed by AWS Rekognition (the second plot above):
| Service | Time for 1000 requests (s) |
|---|---|
| Hugging Face AutoTrain | 35.9 |
| AWS Rekognition | 45.2 |
| Nyckel Image Classification | 65.4 |
| Google Vertex | 95.5 |
With this method, the difference between 1000 predictions on AWS Rekognition and Nyckel Image Classification is only 20 seconds.
Though the Hugging Face inferene endpoint was the fastest, it was the only one that failed with a number of “connection resets.” Likely they have some rate-limiting on the endpoints to stop extremely high throughput.
Takeaway
AWS Rekognition and Hugging Face AutoTrain are the fastest inference endpoints, so if end-user speed is part of your product, these are the best services. However, you might have to include exponential backoff to call the Hugging Face AutoTrain frequently.
Developer Experience
Understanding how these services work for someone new to the field is important. If a service is difficult to use, then it isn’t going to be used.
In fact, this happened with this experiment. Initially we planned to include Azure ML as part of this image classification benchmark. However, poor documentation and the use of opaque quotas to determine training and inference endpoint usage meant we were unable to consistently train and deploy models.
To give you some understanding of how it is to use these services, we looked at five usability metrics giving each service a score out of five:
- Uploading and annotating data
- Level of ML expertise required
- Speed to creating first model
- Speed to first invoke
- Clarity and accessibility of API docs
This is a subjective take on user experience, and if you have more experience with machine learning services, your mileage may vary.
1. Uploading and annotating data
This is the first step that can trip up any new user. If you can’t get your data into the service easily, nothing else matters.
Nyckel Image Classification was the best option here, with the API upload clear and easy to use. Hugging Face AutoTrain was also easy-to-use (mostly) via the UI. Hugging Face is currently updating their AutoML SDK for use with image classification, which will make uploading easier. The ‘mostly’ tag is due to the fact that you have to upload large datasets differently from smaller datasets, and the difference isn’t clear.
AWS Rekognition is easy to upload and annotate if you are already familiar with S3 storage (and ideally the boto3 Python library). Google Vertex AI was most challenging. The method to upload and annotate is well documented with code samples, but you have to set the correct users, credentials, API permissions, and buckets before you can start to upload.
- Nyckel Image Classification: 5/5
- Hugging Face AutoTrain: 4/5
- AWS Rekognition: 3/5
- Google Vertex AI: 2/5
2. Level of ML expertise required
We were testing each of these services from the point of view of someone who had technical experience, but little to no machine learning experience. This represents developers who need to add ML functionality to their product, but aren’t ML engineers themselves.
Nyckel Image Classification was the easiest to use along this axis. You need very little ML knowledge to use this service. You do need to understand what training sets and API endpoints are, but that is about it.
Hugging Face AutoTrain is fairly ML-light, though if you come via the main Hugging Face homepage it can be a little daunting. They talk a lot about the models and datasets in their library, so getting started isn’t as clear. The same for AWS Rekognition. There is a nice flow through uploading->training->deployment for AWS Rekognition that requires little ML knowledge. The only hiccup here is that some of the language is confusing (e.g., understanding the difference between a testing and validation set).
Google Vertex AI requires ML knowledge to use well. There are a lot of options throughout the pipeline, with hidden menus (e.g., you have to know where and how to use your own validation set rather than letting the service choose the validation set).
- Nyckel Image Classification: 5/5
- Hugging Face AutoTrain: 4/5
- AWS Rekognition: 4/5
- Google Vertex AI: 2/5
3. Speed to creating first model
This is different to the training time above, which just the upload-to-invoke time. Speed to creating first model is the time taken from first signing up to the service to having a model created. This tallies with the ‘level of ML expertise required’ above. The services that require little experience are the easiest to create a model with: Nyckel Image Classification, Hugging Face AutoTrain, and AWS Rekognition. The only pitfall for AWS Rekognition is that the Custom Labels option is not obvious to start with so you have to click through a lot until it will let you start a new project. From there though, training is clear.
Again, Google Vertex AI is last. You just need a lot of set up around credentials and permissions before even getting started with the pipeline.
- Nyckel Image Classification: 5/5
- Hugging Face AutoTrain: 4/5
- AWS Rekognition: 3/5
- Google Vertex AI: 2/5
4. Speed to first invoke
Again, this is different than latency. This is how quickly we were able to get to the invoke point.
Nyckel Image Classification performed well here as it’s clear how to invoke each function once it has trained. AWS Rekognition was slightly better than Hugging Face AutoTrain for this metric as you can immediately spin up an inference endpoint for your model within the AWS Rekognition UI flow. With Hugging Face AutoTrain, the inference endpoint it supplies you on the model UI is a test endpoint. This endpoint fails constantly. You have to go to a different UI to spin up a production endpoint.
The Google Vertex AI UI for spinning up an inference endpoint is annoying as you have to deploy the model to an endpoint via the model UI, not the endpoint UI (which you then have to use to delete said endpoint). Another downside for Google Vertex AI (and AWS Rekognition) is that it requires you to call the endpoint using their SDK rather than just giving you a REST endpoint.
- Nyckel Image Classification: 5/5
- AWS Rekognition: 4/5
- Hugging Face AutoTrain: 3/5
- Google Vertex AI: 2/5
5. Clarity and accessibility of API docs
If you are new to using these services, good documentation is critical. Like we said, Azure ML was supposed to be a part of this experiment, but the documentation is extremely poor, with conflicting pages and assumed knowledge throughout.
Conversely, Google Vertex AI’s documentation was very well written. This is the most complicated service we tested, but the fact we could test it with little prior ML experience was down to well-written documentation and good code samples. Nyckel Image Classification documentation is also good, though light.
AWS Rekognition was OK, but it took a while to find the right examples, and we ended up using an external tutorial. Hugging Face AutoTrain was also OK, but it leans towards their text analysis tools and in-built models. Perhaps once their new SDK is updated, their documentation will be updated as well
- Google Vertex AI: 4/5
- Nyckel Image Classification: 4/5
- AWS Rekognition: 2/5
- Hugging Face AutoTrain: 2/5
Developer experience grade
So the final tally of scores shows that Nyckel Image Classification is the easiest to use:

| Service | Uploading and annotating data | ML expertise required | Training time | Time to first model invoke | Documentation | Total |
|---|---|---|---|---|---|---|
| Nyckel | 5 | 5 | 5 | 5 | 4 | 24 |
| Hugging Face AutoTrain | 4 | 4 | 4 | 3 | 2 | 17 |
| AWS Rekognition | 3 | 4 | 3 | 4 | 2 | 16 |
| Google Vertex | 2 | 2 | 2 | 2 | 4 | 12 |
Again, YMMV. If you have more experience with ML services, you might find Hugging Face, Vertex, or AWS better options:
- Hugging Face is going to be good if the dataset you want to use is part of their large library.
- Vertex is going to be good for fine-grained control over your models, training, and deployment.
- AWS is going to be good if you are already embedded in the AWS ecosystem and can leverage existing code/AWS services to use Rekognition.
Takeaway
If you haven’t used an ML service before and need to get a model trained and deployed, Nyckel Image Classification is the best option by far. Once you have a better understanding of the space, the other services become opportunities as well, which you should choose according to your training, accuracy, latency, or pricing needs.
Pricing
If you are using any ML-as-a-Service, there are costs incurred. The pricing models differ between each service:
- Nyckel Image Classification has no cost to train data and a subscription model that charges per invoke.
- Hugging Face AutoTrain has training costs for larger datasets. You can use a free inference endpoint, but it isn’t reliable enough for production. Instead, you can use a dedicated inference endpoint for between $0.06/hr (for a 2GB, 1-core CPU instance) up to $4.50/hr (for a 56GB 4-GPU GPU instance).
- Google Vertex AI charges for both training and inference endpoints.
- AWS Rekognition Custom Labels charges for training ($1/hr) and inference ($4/hr)
So for Nyckel Image Classification, training costs were non-existent. For Hugging Face AutoTrain, training costs were $10-$20 for the largest datasets but free for most.
But for Google Vertex AI and AWS Rekognition, training always comes with a price. As Google Vertex seemed to consistently train for just over two hours, each model cost about $7 to train. For AWS Rekognition, training times varied, with the longest training costing $16.
In terms of inference costs, we weren’t using inference as a regular user would. We were spooling them up, running the test images through them, and then deleting them. This isn’t how people use endpoints. As endpoints have to be live continually to serve customers, it is the cost per hour, month, or year that matters:
| Service | Cost per hour | Cost per day | Cost per month | Cost per year |
|---|---|---|---|---|
| AWS Rekognition | $4 | $96 | $2,922 | $35,040 |
| Hugging Face AutoTrain* | $0.60 | $14.40 | $438.05 | $5,256 |
| Google Vertex | $1.38 | $33 | $1,004.44 | $12,045 |
* this is the pricing for the smallest GPU instance, which is what we used for testing our models
You pay these costs whether your inference endpoint is called once or 1 million times a year. Nyckel Image Classification’s pricing differs in that you are paying per invoke. The highest non-custom pricing is $500/month for 500,000 invokes (Pricing is also tiered with the initial 1,000 invokes each month free). Nyckel Image Classification’s monthly cost in that scenario is more than Hugging Face AutoTrain, about half the price of Google Vertex AI, and much less than AWS Rekognition.
Takeaway
For training costs, Nyckel Image Classification and Hugging Face AutoTrain are the better value. Google Vertex AI is more costly, but by virtue of the consistent training times, also has consistent pricing. AWS Rekognition is costly for running sustained inference endpoints.
For endpoints, Nyckel Image Classification is good for lower invoke counts, and also offers consistent pricing. If you expect high traffic Hugging Face AutoTrain is a better option, though we did experience more failures with this endpoint.
Wrapping up
None of these services has it all.
Nyckel Image Classification is the best all-round. It performs the best when you have smaller datasets, and continues to perform on-par with the other services as your data increases.
Nyckel’s training times are also extremely fast, so it is an excellent choice for prototyping. It is also by far the easiest to use and has the easiest pricing, so it’s ideal for anyone looking to add ML to their product but who doesn’t have a machine learning background or doesn’t want to deal with managing ML infrastructure. The downside is that the endpoint latency is slower than other services, but that difference lessens with concurrent calls.
Google Vertex is a good choice if you have large datasets and accuracy is important. However, the training time isn’t great, nor is the latency, pricing, or ease-of-use. It is more for an experienced ML engineer.
Hugging Face AutoTrain is a Jack of all trades, master of none. It’s not the fastest, cheapest, quickest to train, nor the most accurate. But neither is it the worst at any of these.
AWS Rekognition is easy to use, but training takes a long time. It isn’t an option for quick experimentation, but if you have a good dataset to train a model once on and then deploy to customers, the endpoint is much faster than any of the other services.
This image classification benchmark is on the Nyckel site, so you might consider it biased. Someone with more ML experience might come to different conclusions (and even get Azure to work!). But if you are a developer, product manager, or business founder just looking to add image classification to your product and need a service to help, Nyckel Image Classification is the best option. But don’t just take our word for it. Check out more about Nyckel Image Classification and get all the code you need to re-run these experiments.
Happy modeling!
This image classification benchmark was performed and written up by Andrew Tate of Argot. He has a technical background, but little prior knowledge of training and deploying machine learning models. Our product is built for folks like Andrew who don’t have ML expertise.
Though most of this write-up is done by Andrew, you will see some boxes like this where we couldn’t resist stepping in to emphasize a point.