How to Approach Multilingual Content Moderation

In a perfect world, all users would play by the rules and post only relevant, appropriate content. Since our world isn’t perfect, a robust content moderation solution is the next best thing.
Our world, besides being imperfect, is increasingly interconnected. The internet is more multilingual than ever. If you’re dealing with user-generated content (UGC) in different languages, then you’re most likely going to need a multilingual content moderation solution.
In this article, we’re going to take a look at how the Internet is evolving today in terms of language, as well as some different approaches you can take for your multilingual content moderation needs.
The Evolving Landscape of Languages on the Internet
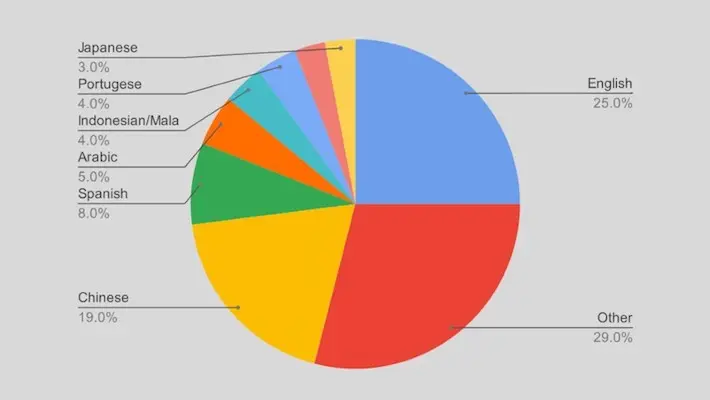
English may still dominate the Internet, but other languages are catching up fast.
Around 70% of Internet users aren’t native English speakers; that fact right there should give you pause. Even accounting for the non-native English speakers who are still using English online, that’s a good chunk of the Internet.
In real life, the percentage of English speakers is even smaller. In fact, over 80% of the world’s population doesn’t speak English as either a native language or at a secondary level.
While English may still be the “lingua franca” for now, the spread of technology around the globe means that more and more Internet users will be looking to read and post content in their own language.
Here are the current top most used languages on the Internet, in basic percentages:

This list is fairly accurate when measured against languages spoken in real life. Chinese (Mandarin), Spanish and Arabic are the top 6 most widely spoken languages in the world today, along with English, Hindi and French.
If your platform caters to users of any of these major languages – or any other language, for that matter – you’ll want to ensure that you can moderate content posted in these languages.
Don’t forget about code-switching, either. This is the uniquely online phenomena of users switching between different alphabets and/or languages (usually including English), effectively creating a whole new language.
For example, “Arabizi” is the Arabic language written in Latin script, used widely by much of the younger Arabic-speaking generations online. “Taglish” (Tagalog + English), “Hinglish” (Hindi + English), “Portuglish” (Portuguese + English) are just a few other examples.
Code-switching may in fact be more common for a lot of text UGC than an actual standard language, since Internet users tend to be inventive and go with whatever mode of communication is easiest.
Choosing the Right NLP Model
Unless you have the time and resources for human content moderation, you’re going to need an AI solution.
It’s important that you choose a natural language processing (NLP) model that’s trained with a dataset in the language – or languages – you need. Some datasets out there are trained on just one or a few languages, while others are truly multilingual.
You may need a model trained for multiple languages, but again it depends on your platform and target user base. To give you an idea of what’s out there, here’s a sample of some of the most-downloaded text classification models from AI community Hugging Face:
| Model name | Languages supported |
|---|---|
| distilbert-base-uncased-finetuned-sst-2-english | English |
| unitary/toxic-bert | English |
| ProsusAI/finbert | English |
| Hate-speech-CNERG/indic-abusive-allInOne-MuRIL | Bengali, Devanagari Hindi, Code-mixed Hindi, Code-mixed Kannada, Code-mixed Malayalam, Marathi, Code-mixed Tamil, Urdu, Code-mixed Urdu, English |
| tals/albert-xlarge-vitaminc-mnli | English |
Unsurprisingly, most of these models use datasets trained in English since English continues to dominate web content (for now).
That said, #4 is a good example of a model that has been comprehensively trained with a dataset that detects not only several South Asian languages, but code-switching between those languages as well.
Just because a model works for a lot of platform owners doesn’t mean that same model will work for you. If you have more of a niche platform with a user base that only uses one language, you’ll need something more specific.
Here are several examples from Hugging Face of models that have been trained for a more specific purpose, on a single language:
| Model Name | Language |
|---|---|
| pin/senda | Danish |
| turing-usp/FinBertPTBR | Portuguese |
| HooshvareLab/bert-fa-base-uncased-clf-persiannews | Persian |
| uer/roberta-base-finetuned-dianping-chinese | Chinese |
| Tatyana/rubert-base-cased-sentiment-new | Russian |
If your user base is multilingual, you’ll want to go with a model trained for multiple languages, including your own.
Here are some more examples from Hugging Face:
| Model Name | Languages |
|---|---|
| bert-base-multilingual-uncased-sentiment | English, Dutch, German, French, Italian, Spanish |
| xlm-roberta-base | English, Afrikaans, Amharic, Arabic, + 91 more |
| amberoad/bert-multilingual-passage-reranking-msmarco | English, Afrikaans, Amharic, Arabic, + 98 more |
Model choice matters a lot when it comes to creating the best experience possible for your users. This is perhaps even truer in the case of multilingual content moderation, since you have to trust that the model is adept at understanding and moderating content in all the languages it’s been trained in.
Don’t feel like you have to go with the first model you pick. You’ll want to try different models to ultimately see what works best for your data.
Conclusion
English still dominates the web, but other languages are catching up – especially other major world languages including Chinese.
Since web users prefer to post content in their native language – or sometimes code switch between languages – it’s important to have parameters in place to moderate content in different languages. Look for models trained on the language(s) you need and don’t be afraid to try more than one.
If you’re having trouble finding the right fit, Nyckel can help. Nyckel is an ML (machine-learning) API platform that will take your data and try out different models and hyperparameters to find the one that works best for you.