Google Cloud Vision API Class List: Can We Reverse-Engineer to Find the List?

What is Google Cloud Vision API?
Google released its Cloud Vision API in 2015 as a computer vision API that enables developers to incorporate image recognition, detection, and classification features into their applications. The Cloud Vision API utilizes pre-trained models to identify several image elements, including objects, faces, text, barcodes, landmarks, and more.
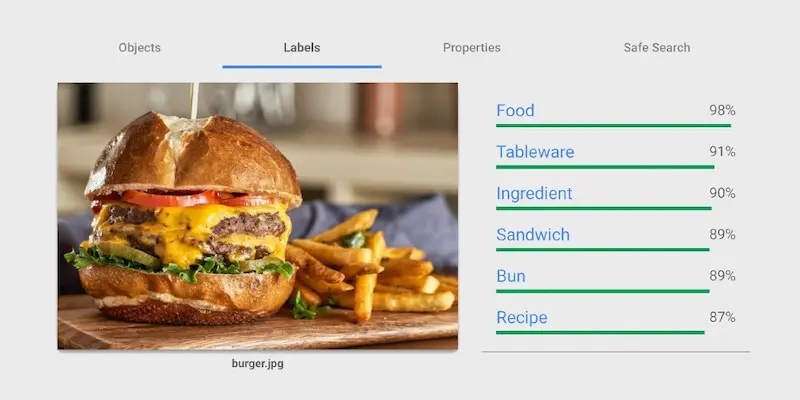
This post will focus on Google Cloud Vision API’s “Label Detection” feature, which utilizes machine learning to automatically tag images with relevant labels based on their content. You can try it out for yourself, but here is an example:

What is the class list, and why is it important?
The class list is the complete list of all possible labels that Google’s pre-trained model can assign to an image. Google uses these pre-defined labels for both broad and specific categories. When an image is submitted, the Cloud Vision API returns a list of relevant labels from the class list that apply to that particular image.
When using pre-trained models, it’s critical to understand the class list (i.e., vocabulary) that a multiclass or multilabel classification API uses. We’ll illustrate the importance of this through an example; let’s say you operate a used car marketplace and want to automatically classify photos uploaded by your sellers.
- First, you want to confirm that you can map the API’s vocabulary to yours. For example, if you want to classify images that contain cars, you want to ensure that the class list contains “car.” If the list doesn’t have that category, is too coarse-grained (e.g., only includes “vehicle”), or only contains a non-exhaustive list of sub-categories (e.g., only “Ford F-150” and “Toyota Camry”), then it won’t work for you.
- Next, you want to do the actual mapping. Sometimes this is as simple as mapping “car” from the API to your “car.” But often, it’s more complicated. You may have to map multiple sub-categories like “sedan” and “hatchback” to “car” and keep track of this mapped list in case it changes. You may also have to check for the presence of multiple labels on a single image. For example, “car” and “headlights” to make sure you get the front view of a car.
Google, unfortunately, doesn’t publish this list anywhere, so we wanted to use a public dataset to try to reverse-engineer some or most of this list.
How did we reverse-engineer the class list?
Our general approach was to invoke the API with a large and varied dataset of images and accumulate the set of unique labels found. The code is available on GitHub, but here’s a description of the important steps:
-
Downloaded the dataset and picked random images
We used the Laion400m dataset, a large and diverse dataset of links to images on the public web. The searchable dataset is split into several parquet files, each containing links to images along with metadata about the image, like image resolution.
We read one random file at a time, filtered out images smaller than 224px on either side, and selected 100k image URLs at random. Later in the notebook, we called the Cloud Vision API on these images and accumulated a list and count of new unique labels found. We then came back to pick a new random set of images from a new random file to repeat the process until we were satisfied with the unique labels we’d accumulated. -
Removed dead links
The Laion400m dataset is several years old, and many links were dead. We filtered out dead links by making an HTTP HEAD request to the URL and checking for success. This step narrowed our list from 100k links to about 75k working links.
-
Called the API and stored unique labels
We called the API and accumulated a list of the unique labels we found. We did this in parallel across 15 threads to make the process faster. The process took roughly an hour for ~80k images. When we were done, we wrote the unique labels.
-
Graphed the count of unique labels discovered
We graphed the number of unique labels found as a function of the number of images processed. The idea was that this line would start to steep as each new image discovered a large set of new labels but would level off over time, hopefully completely flattening out after some time.
Using this method, we could never guarantee that we would get the entire class list, but from looking at the shape of the plot in the next section, you can see that we retrieved a large majority of it.
Results
We called the Cloud Vision API with over 400k images and accumulated a list of unique labels returned. Here is the count of unique labels graphed over the number of images processed:

We were hoping to get to the “end of the rainbow” and see that graph fully flatten out - to the point where there are few new labels to be discovered from processing more images. But after several hundred dollars paid to Google, and several hours spent processing over 400k images, we had to call it a day. Here’s what we found:
See the complete list of Cloud Vision API labels, sorted alphabetically.
Many of the items on the list are unsurprising, but there are several obscure words that I had to look up definitions. Here’s a small sampling of these: Accipitriformes, Alcapurria, Bigoli, Bredele, Calamondin, Carcharhiniformes, Coenagrion, Dongfang meiren, Ekiben, Eumeces, Frikadeller, Hamantash, Khinkali. See how many of them you know without having to look it up.
It is truly impressive that Google can detect such a diverse array of items. But that only helps if your application’s needs match Google’s vocabulary. Let’s consider how Google Cloud Vision’s API class list would work from the perspective of the used car marketplace example. The class list has a mix of:
- Specific car models like “Ford fairlane crown victoria skyliner” and “Chevrolet Corvair,” but the list is not very exhaustive. Even best-sellers like the Toyota Camry and Ford F-150 aren’t on it.
- Vehicle makes like “Maserati” and “Audi,” but this list is also not very exhaustive. Some popular makes are missing, and many makes only have a small subset of models listed, with the make not listed by itself.
- No categories like “car,” “sedan,” “SUV,” “pickup,” “hatchback,” etc. are present.
You’d be out of luck if you had to categorize uploaded photos by make and type of vehicle (sedan, hatchback, etc.).
________________________
If the class list of pre-trained models is not cutting it for you, consider Nyckel. Nyckel makes it easy to train image classification and tagging functions tailored to your data and use case. Check out this 1-minute video to see how easy we make it, or sign up for a free account to try it out for yourself.