AutoML benchmark: Nyckel vs Google vs Huggingface

My name is Oscar and I’m a co-founder of Nyckel. We have developed a site that allows anyone to train and integrate a Machine Learning (ML) model into their application, and do so in less than an hour. We have put a lot of work into our Auto-ML system and in this blog post I’m excited to share some benchmarking results against Google Vertex AI (formerly Google AutoML) and Huggingface AutoNLP comparing accuracy, training times and invoke latencies.
I use two public datasets: IMDB, a movie review sentiment classification benchmark, and AG News, a news classification benchmark. I use a fixed test-set of 1000 samples for all experiments and varying amounts of training data with 20% of the training data set aside for validation. All results are reproducible using the public codesamples.
The need for speed
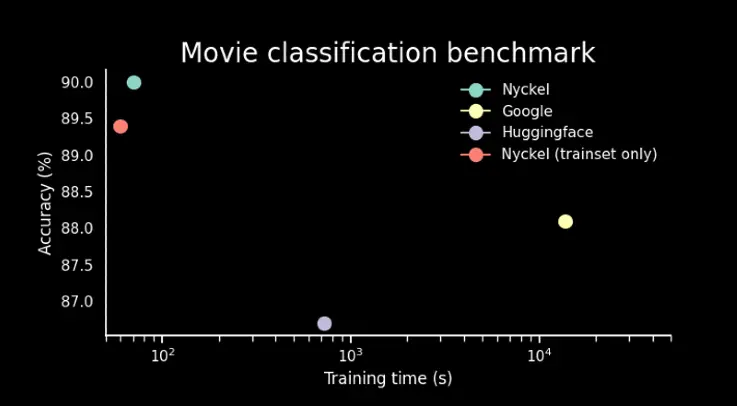
In the first experiment I train a model using 500 samples from IMDB and plot training time vs accuracy.
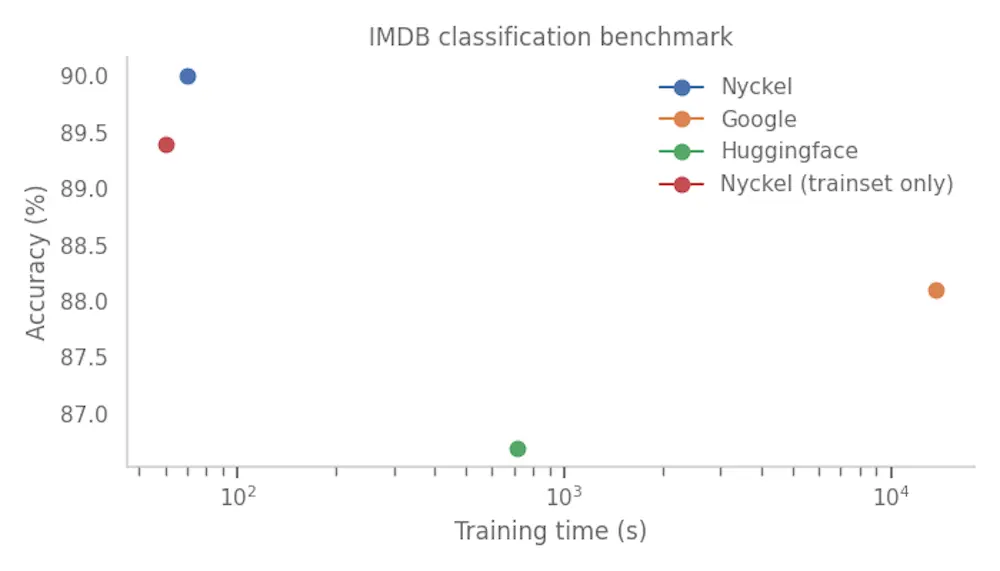
A few things to note about this plot. First, the x-axis is in log scale. This means there is literally an order of magnitude difference between the Nyckel and Huggingface (HF) and Google training times. Second, all providers returned highly accurate models (>86% accuracy) with Nyckel and Google outperforming Huggingface. Third, there are two measurements for Nyckel. The reason is subtle. Nyckel uses cross-validation to determine the best model for the data while Google and HF require fixed validation splits. For example, HF requires the user to pick a model based on the performance on the validation set using the CLI.
The use of cross-validation allows Nyckel to train on all 500 samples in the train and validation sets combined. To even the score I therefore re-ran the Nyckel experiment while only providing the 400 samples in train. Regardless, it appears Nyckel is able to train a more accurate model and do so much faster. How is it possible?
Reverse-engineering the HF CLI outputs it appears likely that they do deep fine-tuning of the networks. The model status page suggests that they are provisioning compute nodes (1–3 minutes), starting them up (1–2 minutes) and then training (5–10 minutes). As a result, it took around 12 minutes to train a model on the 500 IMDB dataset. Google VertexAI, on their end, required 5 hours to come back with a model. I honestly don’t understand what they are doing with all that time. The one thing I can think of is if they apply Network Architecture Search (NAS); but if they do, they are not very successful judging by the results in this benchmark.
The Nyckel AutoML engine, on the other hand, is based on meta transfer learning. It’s “transfer” because it leverages a large set of pre-trained neural networks to represent your data, and it’s “meta” because we make informed decisions on which of the representations to try based on your particular problem. The design allows for a highly parallel execution where features are extracted and models trained by 100s of compute nodes in parallel requiring only 10s of seconds to train even with 1000s of samples. In this case the IMDB 500 results came back in ~60 seconds. Re-training after changing or adding annotations only took ~15 seconds.
While deep fine-tuning and Network Architecture Search should in theory yield superior accuracy to transfer learning, these experiments indicate that this is not always the case, in particular in the low-data regime. Also, as shown, it takes orders of magnitude longer to train.
So is there a need for such rapid training times? I’d argue there is. As has been extensively shown and argued it is the data that matters when trying to improve a ML model. Specifically, one needs to iterate over and over between training, reviewing model outputs, identifying issues and annotating more data to address those issues. Nyckel’s fast training time and integrated data-engine allows you to do just that.
Training size sweep
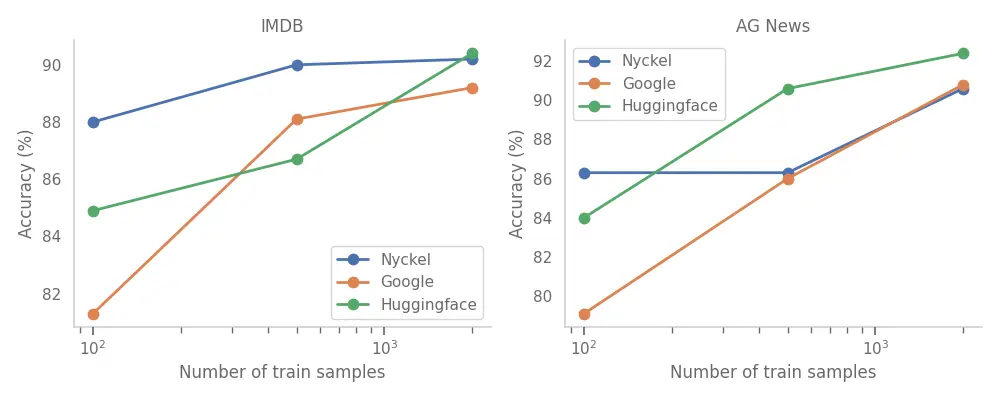
To ensure that the accuracy in the previous section isn’t an outlier I added one more dataset and trained with three different train set sizes. No clear winner emerged from these results. Nyckel did best on IMDB, in particular in the low-data regime while Huggingface did best on AG News, in particular in the high-data regime. Training times did not change much within this range of training set size: Nyckel remains around 1 minute, Huggingface around 12 minutes and Google around ~5 hours.
What about inference?
A key features of ML platforms is to provide API endpoints to invoke the trained models on new data. The three services benchmarked all provide such endpoints. Using the 1000 samples in the test-set I measure the end-to-end invoke latencies for a single call.
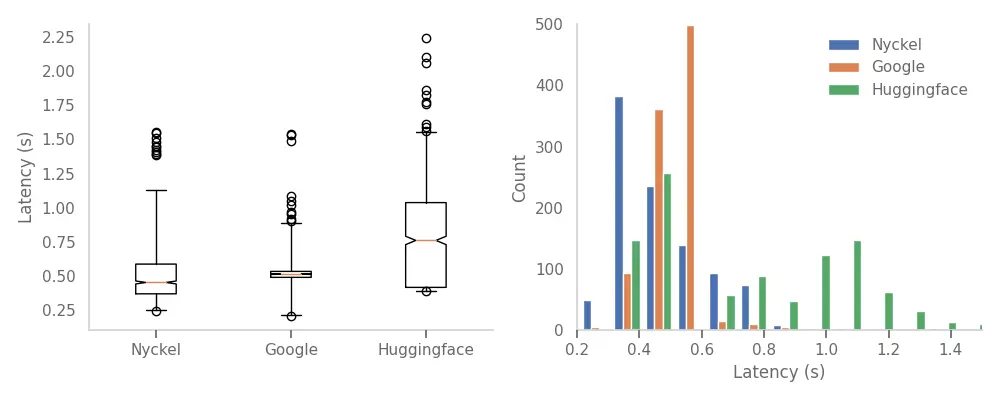
From this data it appears Nyckel is the fastest, completing most invokes within 400ms. Google does second best with most calls finishing in 600ms. Huggingface (HF) has two modes: around half the calls are centered around 450ms while the other half take much longer, around 1s.
In summary
In this blog post I shared some benchmarking results comparing Nyckel’s AutoML system against Google’s Vertex AI and Huggingface’s AutoNLP. No clear winner emerged with respect to model accuracy although Nyckel tended to do best in the low-data regime (up to ~1000 samples). However, there were large differences in training time with Nyckel training in ~1 minute compared to ~12 minutes for Huggingface and ~5 hours for Google. Nyckel also provided the lowest latency invokes followed by Google and then Huggingface.
At Nyckel we are actively working to reduce latency, improve training times, and adding more models templates to our library. We will continue to share updates as they become available.
Let me know if you have issues replicating these results, or want to learn more about our design!