End-to-End AutoML: Your AutoML Platform Should Span the Entire ML Development Lifecycle

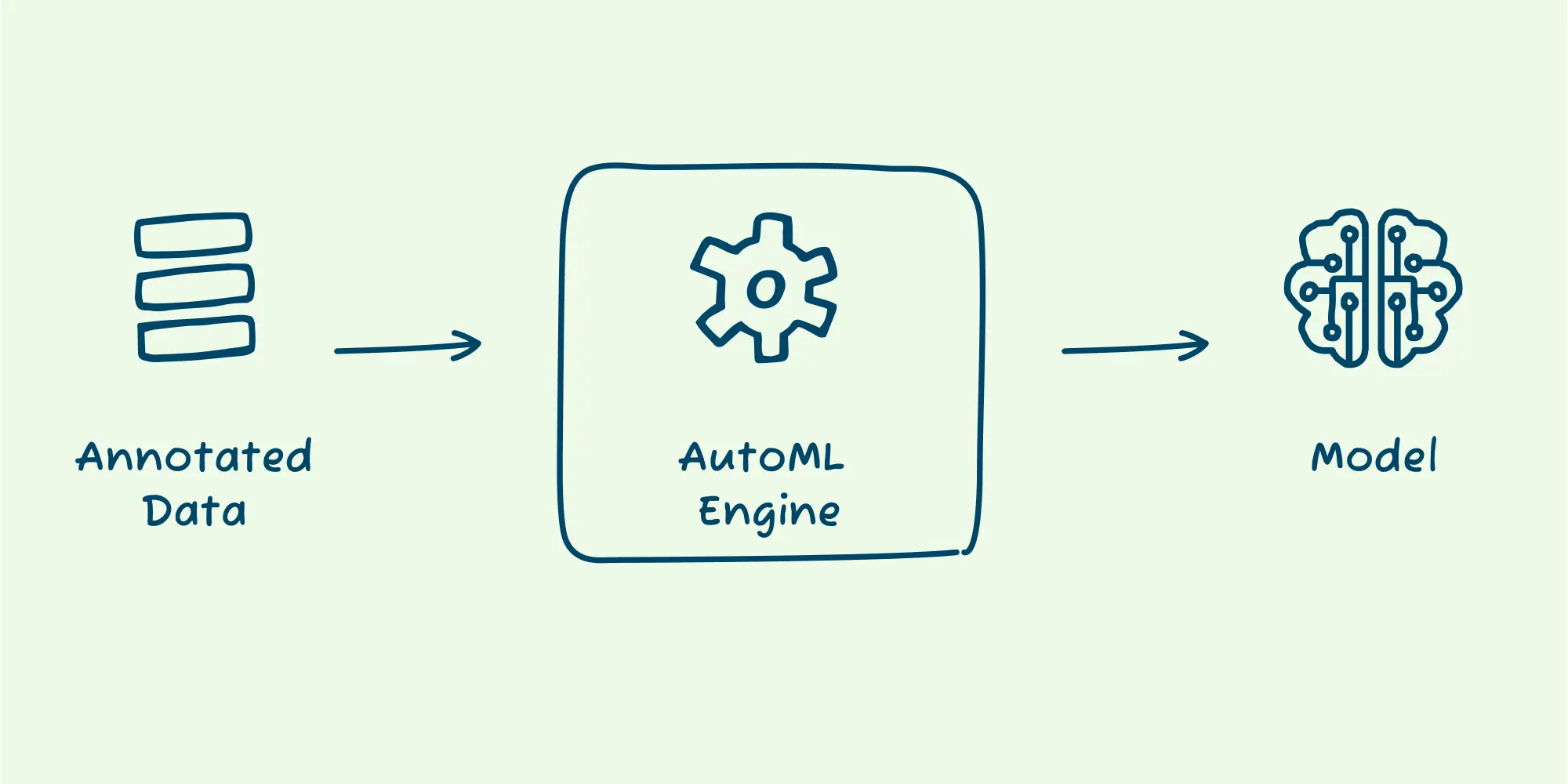
In our previous post, What is AutoML? A Comprehensive Guide & What It Means for Product Teams, we talked about what AutoML is and how it’s a huge help in making ML accessible to non-experts. We mentioned how AutoML takes your annotated data and produces a model, automating most of the work an expert would perform in this process. This automation makes the process faster, less error-prone, ensures you follow best practices, and makes it possible to train a model without ML expertise.
In this post, we explore why an AutoML platform can and should do more than just model training.
Examining the goals of AutoML
AutoML services and libraries exist for three reasons:
- To enable folks without ML expertise to train a model from labeled data,
- To automate the tedium and undifferentiated heavy lifting involved in training an ML model, and
- To reduce mistakes by encoding best practices.
Simplifying the ML development process with AutoML is appealing even to those with ML expertise.
While most AutoML platforms focus only on model training, the tedium, best practices, and need for ML expertise doesn’t begin and end there. Instead, they apply to the whole ML development lifecycle. As such, to really fulfill the goals above, AutoML platforms need to expand their scope beyond just model training.
ML is about more than just training a model
Training a model from labeled data is just one of many steps that require expertise when using ML in real-world systems. Let’s look at a few other activities in the typical ML development lifecycle:
Data annotation
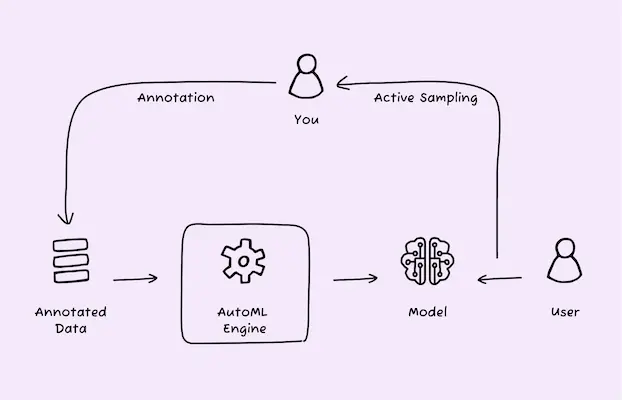
Before you can train a model, you need to manually annotate some data. A good annotation user experience is important because it makes annotation faster and less error-prone, which leads to more and higher quality annotations. Once an initial model is trained, active learning can be used to make sure the right data is annotated. For example, the platform should capture data from model invokes for rare classes, data similar to where the model makes mistakes, and data similar to where the model makes low-confidence predictions. Doing this requires the annotation tool to work closely with a trained model.
Model deployment
An AutoML engine gives you a model, but you are responsible for deploying it. This may seem trivial compared to training a model, but it is not. There are several things to consider:
- What is the right-sized hardware for deploying the model that optimizes cost, latency, and throughput?
- How will this hardware scale with your usage patterns? Will it handle a spike in usage? Will you incur cost even for periods when the model is not in use?
- What should the API for calling the model look like? How will Auth be handled for this API?
- How can multiple versions of the model be deployed side-by-side (for testing and gradually rolling out a new model)?
Model monitoring
Once you deploy a model and are using it in production, you will need to monitor its performance. Here are two common changes to monitor for:
- The type and/or distribution of data you are getting may shift from the training data. For example, using an ML model to block spam could change the type and frequency of spam you get as spammers try to get around the model.
- The distribution of model inference outputs can change. Using the spam example above, you may see that the percentage of reported spam has dropped over time. This could be because spammers got tired of being blocked by the model or because they are using different kinds of spam that the model is not catching.
Generally, these are cases where changes (i.e., drift) in the data cause a degradation in model performance. You need to monitor model performance to spot when data drift is happening. Ideally, you will automatically gather new data and retrain your model over time to reduce the chances of drift.
Data inspection
You have trained a model, but you notice that its accuracy is low. To improve your model, you’ll want to inspect your data to see where the model disagrees with your annotation and see examples of where the model has low-confidence predictions. In the process, you may find erroneous annotations or examples of the types of inputs that the model gets confused about. You can improve the model by fixing these erroneous annotations and adding more examples of data that are confusing the model.
Adding humans in the loop
ML models are not perfect, and it’s a good idea to have a human reviewer in the loop to review model outputs. However, having the reviewer look at all outputs of the model makes little sense because that negates the usefulness of doing ML in the first place. What data should the reviewer look at? A random subset of data is a starting point, but to make the review most effective, you’ll want to augment this with active sampling techniques that capture important data like:
- Model outputs where the confidence score is low
- Model outputs for rare classes (rare in output frequency or training data frequency)
- Model outputs that are problematic from the standpoint of your business (have a higher consequence when it’s wrong, have been flagged by a user, etc.)
- Model inputs that are similar to other data points where the model made mistakes or had low-confidence outputs
Once you have a reviewer in the loop, you also want to feed back the human-reviewed results as annotations to the training process.
Model evolution
The needs of your customers are rarely static, and as your product evolves, the ML model(s) will need to evolve alongside it. For example, say you have a car review website, and you use a classification model to separate “interior” and “exterior” photos. If you receive feedback from your readers that they’d like to see “dash,” “front seat,” and “rear seat” photos separately, you’ll have to evolve your classification model to add these new labels.
Model testing and rollout
Once you’ve done a round of iterating on your data and retrained your model, you’ll want to test the new model to make sure it still performs well against some common important cases. You’ll then want to roll it out to your customers, gradually shifting traffic from the old model to the new one. As you do this gradual rollout, you’ll want to monitor and compare the new model to the old one to see if there are any unexpected and drastic changes in the distribution of outputs.
ML development is all about iterative loops
Though it was broken down into separate activities above, the ML development lifecycle, like the software development lifecycle, is all about iterative loops of activities.
Iterating on your data
Andrew Ng talks about the importance of data-centric AI — focusing on the quality of data as the best way to create a good model. The process of improving the quality of the data is an iterative one:
- Annotate some data
- Train, test, and deploy a model
- Use the model to discover erroneous annotations and fix them
- Use the model to discover “areas of data weakness”
- Capture more data, using active sampling techniques to focus on important data, and ideally from recent production data
- Return to step 1
Even after you are satisfied with the performance of your model, you will need to periodically iterate on your data to account for data drift. The more you iterate on your data, the better the model and, in turn, your product will be. The easier and faster it is to iterate on your data, the more likely you are to do it.

Iterating on your product
As you work on your product and talk to your customers, you may discover that the model needs to change. To repeat an example used earlier, say you own a car review website, and you’ve been using image classification to organize car images as either “interior” or “exterior,” but you’ve received customer feedback saying they’d like to see “dash,” “front seat,” and “rear seat” photos separately. You’ll need to modify the model to add these new labels, annotate some data, and go through the data iteration flow above until you get good performance.
An end-to-end AutoML platform enables fast iteration
The speed of iteration is paramount in software and ML development
Speed matters in the iterative loops mentioned above. If the model can be trained and deployed in seconds, provide feedback on accuracy improvements and annotation mistakes, and guide you to what data you should annotate next, ML development turns into an interactive experience. As a result, you are much more likely to want to spend time doing it.
On a slightly longer timescale, how quickly you can take your idea for an ML model to production matters. The less time you think it is going to take, the more likely you are actually going to do it, and the higher the return on investment.
Lastly, continuous deployment is an accepted best practice in software development, with daily (or even more frequent) deployments being the standard. ML development should follow the same example. This is only possible, both from a pure physics standpoint, and from team enablement and motivation standpoint, when iterations in the ML development lifecycle are fast. There would be no continuous software deployment if your code → build → test → run cycle took 3 hours, and the same is true for ML.
Importantly, the relationship between speed of iteration and your ability to deliver a good product is not linear. The experience when going from a 3-hour training cycle from a 1-hour training cycle, or from a 3-month model development cycle to 1-month will not be that different. But it will feel very different when you have a 60-second training cycle and a 1-day timeframe to take an ML idea to production.
You need an end-to-end AutoML platform for speed
The activities and loops mentioned above are highly interconnected. For example, the data iteration loop requires close co-operation between an annotation tool, a data exploration tool, a model training tool, and control of model deployment. While it is possible to stitch together separate tools to get the job done, this will increase friction, frustration, and time spent on each step of the process. For example, how will your annotation tool make its annotations available for training? Do you have to export some json file alongside your data and import them both into your training tool?
In contrast, an end-to-end AutoML platform that is built from the ground up to enable fast iteration will enable productivity and velocity throughout your ML lifecycle. Such a platform would have:
- A user-friendly annotation experience that instantly sends annotated data to…
- A fast AutoML engine that trains in seconds/minutes and automatically retrains any time there is new data
- A model deployment mechanism that instantly deploys newly trained models to elastic and scalable inference-optimized hardware
- An always-on active sampling process that samples incoming model invoke data to extract important data for human review and annotation
- A data explorer that enables you to inspect your data along various axes
The whole is greater than the sum of its parts
When all the parts above come together, the experience feels magical. See this 60-second video to understand what we mean. For a comparison to the software development world, the experience is similar to using Vercel or the old Heroku compared to setting up infrastructure, CI/CD pipelines, preview environments, CloudFront, and monitoring on AWS.
We built Nyckel as an end-to-end AutoML platform, so you can train and deploy machine learning functions without writing code or dealing with infrastructure. Sign up for a free account to get started or reach out to us if you have any questions about how Nyckel could work for your use case.
This post is the second in a series of articles about AutoML and what it offers organizations looking to implement ML. The first article of this series was an intro to AutoML and the final article shares nine features your AutoML platform should include.