Building a Recommender system using the Nyckel API.


Intro
How does Spotify or Netflix recommend content to their users? How does Amazon recommend products? They both use so-called Recommender systems and in this post we break down some common algorithms. We then show how they can be decomposed into simple Machine Learning functions using the Nyckel API.
Music Recommender example
Let’s use a concrete example: a music recommender. In this example we have three components: Users, Albums and Interactions.
Users
| Id | Name | Age | Location | Gender | … |
|---|---|---|---|---|---|
| 0 | Oscar | 43 | Santa Cruz | Male | … |
| 1 | Dan | 42 | Santa Diego | Male | … |
| … |
Albums
| Id | Name | Artist | Year | Style | … |
|---|---|---|---|---|---|
| 0 | Freewheeling | Bob Dylan | 1963 | Folk | … |
| 1 | Origin of Symmetry | Muse | 2001 | Electronic Rock | … |
| 2 | Abbey Road | Beatles | 1970 | Rock | … |
| … |
Interactions
In this example “preferences” is some measure of how much a user likes a particular album. For example by measuring how much time they spend listening to it.
| Id | UserId | AlbumId | Preference | … |
|---|---|---|---|---|
| 0 | 0 | 0 | 90% | … |
| 1 | 0 | 1 | 85% | … |
| 2 | 0 | 2 | 79% | |
| 3 | 1 | 0 | 92% |
The problem statement now becomes:
Given a user, what albums should we recommend?
Solution space
There are two main sources of information to draw from: Content and Interactions. There are also several hybrid methods which combine both sources.
Content filtering
Following our example, Content filtering uses either the Users and Albums tables, whichever holds the most information to meaningfully measure similarity.
Do we have enough meta-data to know if a user is similar to other users? For example, people of a certain age, gender and location may have similar music preferences. If so, recommend albums that users in that group tend to like.
Do we know what music the user listens to? And do we have good meta-data on the Albums table to identify similar music? If so, recommend albums that are similar to the ones the user already listens to.
Collaborative filtering
Collaborative filtering doesn’t group users or albums by their respective meta-data. Instead, it relies on the interaction table and infer preferences that way. For example, user “Oscar” listens to similar things that users “Dan” and “George”, so he is likely to like other albums that they like. This is appealing since we don’t have to rely on any explicit meta-data in the Users or Albums table.
Recommender systems using Nyckel
Let’s now look at how to implement a Recommender system using the Nyckel API.
Content filtering using Nyckel
Content-based filtering using images or text can be implemented using nearest neighbor search. For example, if you have rich meta-data for each user, try Content-based filtering on the Users table like so:
- Concatenate the entries in each User table row and add to a Nyckel Text Search function.
- Query using the new User and retrieve the most similar users.
- Recommend the albums they listen to.
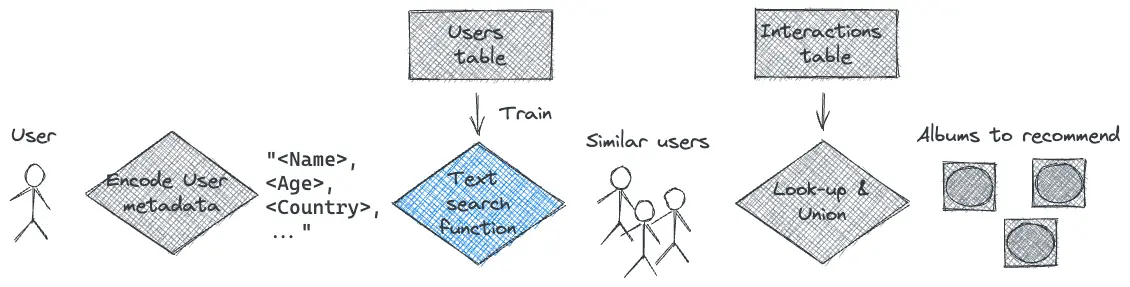
Conversely, if you have rich album meta-data, you can try filtering like so:
- Concatenate the elements in each Album table row and add to a Nyckel Text Search function.
- For each album that the new user likes (if you know them) query for similar albums.
- Recommend the intersection (or union) of the retrieved albums.
Collaborative filtering using Nyckel
The Interactions table is at the core of Collaborative filtering. However, the examples discussed below should be considered Hybrid since meta-data from the Users and Albums tables is used. A pure Collaborative implementation would use only the album ids.
Collaborative filtering can be posed as classification where the input is a User and the output is an Album. Granted, in some situations it might be an “extreme” classification problem with 100,000’s of output categories. Still, it is a classification problem.
The challenge arises due to the User context. Clearly, it is not enough to provide a UserId or Name – we must somehow encode the interaction and meta-data into the input so the classifier has access to it. So this becomes a context encoding challenge. We will look at two ways of doing this below. Let’s first look at how it all would fit together using a Nyckel Text Classification function.
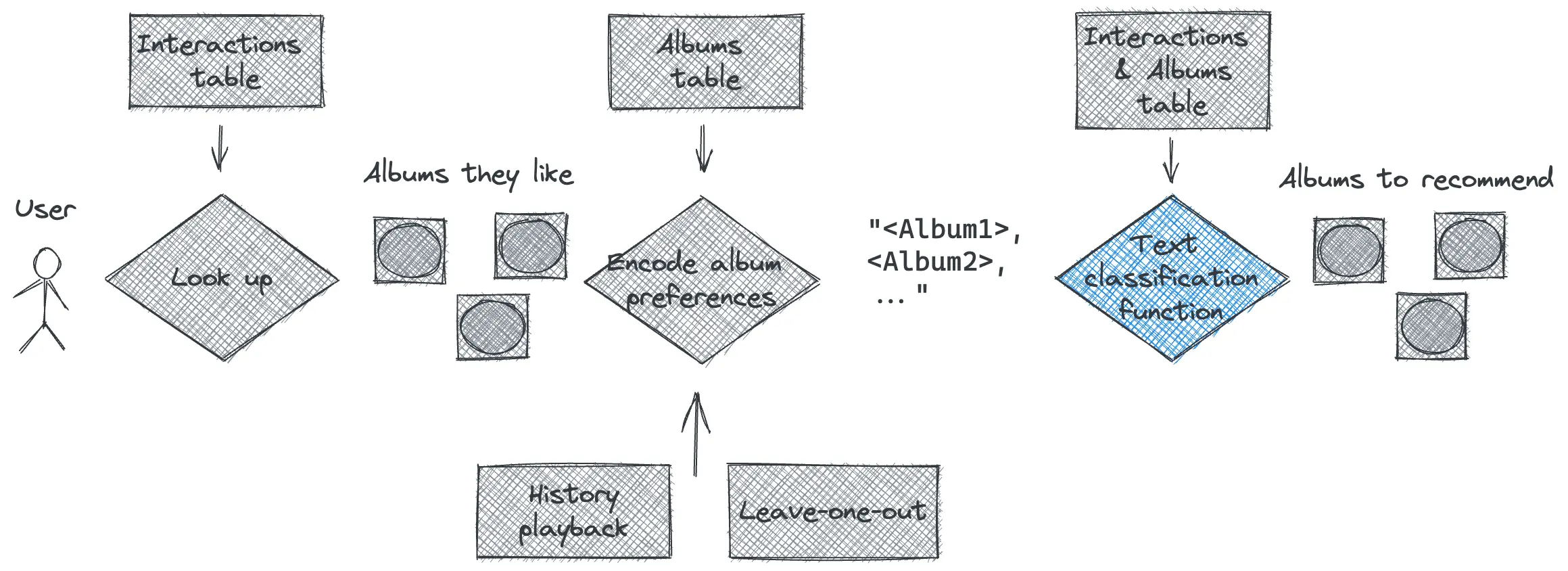
The core idea is that the Text Classification function is trained to associate a set of album preferences with a new album. So how to create train samples from the music preferences? We look at two ways next.
Leave-one-out
Since we know Oscar likes three albums, we create three input-output examples by holding out one of the albums. For Dan, we only have one data-point so we can only create one input-output example. Let’s call this method of encoding leave-one-out.
| Input | Output |
|---|---|
"Freewheeling, Origin of Symmetry" |
Abbey Road |
"Abbey Road, Origin of Symmetry" |
Freewheeling |
"Freewheeling, Abbey Road" |
Origin of Symmetry |
"" |
Freewheeling |
Note that the preferences of the Interaction table is binarized. Also note that while the input is a String, the output is a Category (in this case an Album).
leave-one-out encoding ignores the temporal ordering of how users came to like these albums. If this ordering is important in your application you can try history-playback encoding instead.
History-playback
As an alternative encoding, we can instead play back the history and add a training sample for each point in the preference history. For Oscar, let’s say that he first liked Freewheeling, then Origin of Symmetry and finally Abbey Road, then the samples table might look like this. Let’s call this encoding history-playback.
| Input | Output |
|---|---|
"" |
Freewheeling |
"Freewheeling" |
Origin of Symmetry |
"Freewheeling, Origin of Symmetry" |
Abbey Road |
"" |
Freewheeling |
Updating the training data
Let’s say a user likes N albums and we have already created samples to reflect this. Now they like a new album. How do we incorporate this new information?
history-playback has a notable advantage here in that it’s trivial to add new preferences. For each new album that a user likes, you just create one new sample. Using leave-one-out, on the other hand, requires deleting the previous N samples and creating N+1 new ones.
Encoding recency bias
People’s preferences typically change over time, both at the personal and group levels. How do we account for this using Classification? The most straightforward way might be to delete old samples from the training set. Another way might be to give preference to newer albums in the set that is eventually shown to the user.
Encoding User meta-data
As mentioned above, the Collaborative filtering method outlined above was actually a Hybrid method since it relies on the Album meta-data. The Wikipedia page on Recommender systems lists several other Hybrid flavors.
In our running example, one could use the history-playback encoding together with user meta-data in a Nyckel Tabular Classification function as shown below. This encodes user meta-data as part of the input in addition to the interactions.
| Age | Gender | Location | Albums | Output |
|---|---|---|---|---|
| 43 | "Male" |
"Santa Cruz" |
Freewheeling | |
| 43 | "Male" |
"Santa Cruz" |
"Freewheeling" |
Origin of Symmetry |
| 43 | "Male" |
"Santa Cruz" |
"Freewheeling, Origin of Symmetry" |
Abbey Road |
| 42 | "Male" |
"San Diego" |
Freewheeling |
Conclusion
Recommender systems are powerful systems that help users find relevant content and products. There are several ways to implement a recommender system, where one might focus on the content or the interactions. We have discussed a few ways one can use the Nyckel API to quickly bring up a Recommender system.